

5 min read
|
84% of developers use AI tools and daily users merge 60% more PRs—but AI-coauthored code shows 1.7x more issues. This article analyzes the real productivity data, the hidden quality costs, and the architectural patterns for safely integrating AI coding into enterprise SDLC. |
The Productivity Paradox
The METR AI Tools Study published in January 2025 produced a result that should be on every engineering manager's reading list: experienced developers working on AI-assisted tasks were 19% slower than the same developers working without AI assistance, despite reporting feeling 20% faster. The subjective and objective metrics pointed in opposite directions.
This is not an argument against AI coding assistants. The GitHub Copilot research shows genuine, replicable productivity gains: 55% faster task completion in controlled studies, 126% more projects completed per week, 60% more PRs merged for daily users. These numbers are real. The METR finding does not contradict them—it contextualizes them.
The resolution is task type. AI coding assistants produce measurable productivity gains on well-specified, self-contained tasks with clear success criteria: implementing a function from a specification, writing unit tests for existing code, generating boilerplate for known patterns. They produce neutral or negative productivity outcomes on exploratory, architecture-level, or ambiguously specified tasks where the main cognitive challenge is not writing code but deciding what code to write.
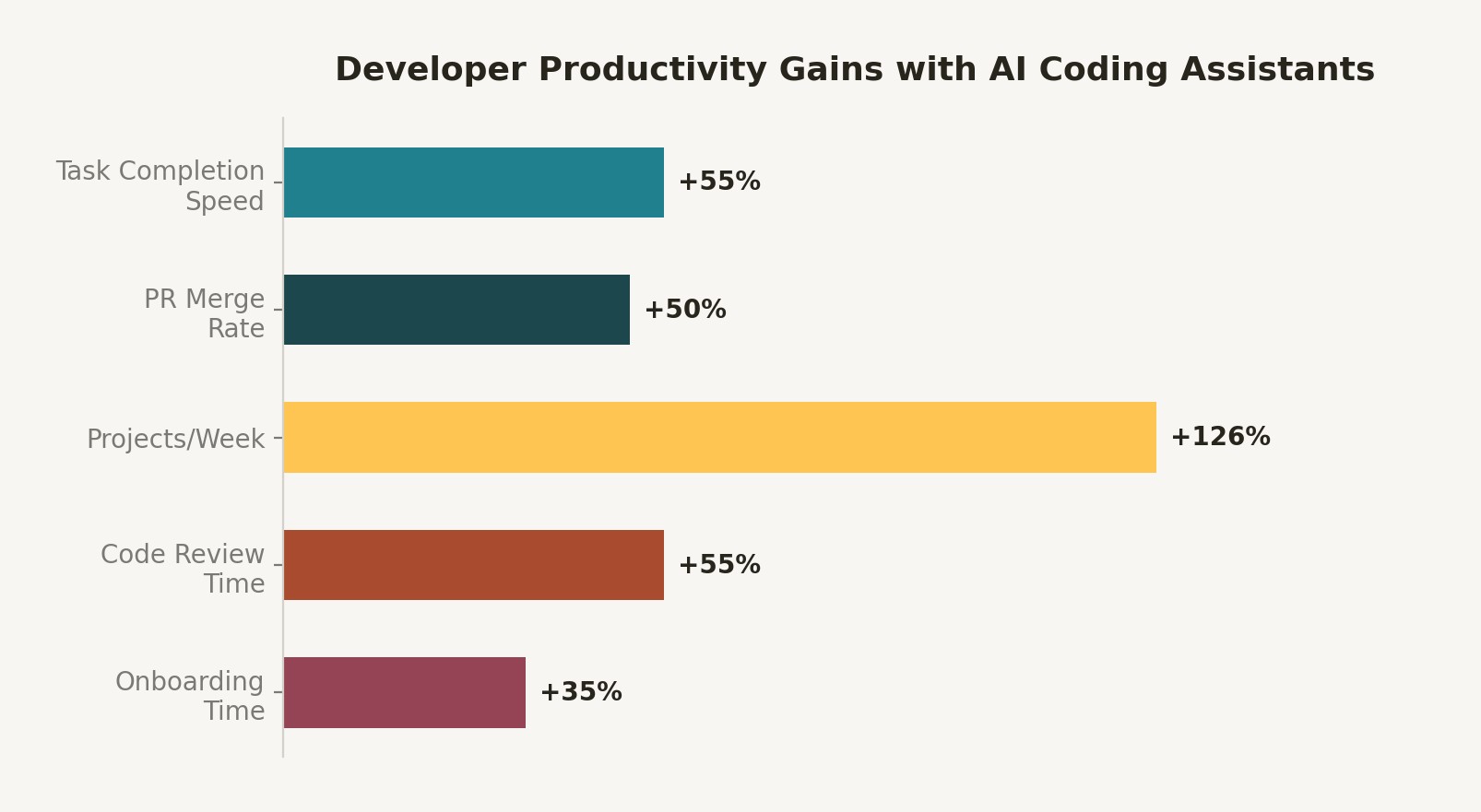
Figure 1: Developer productivity metrics by AI tool usage pattern. Task type is the primary moderating variable in productivity outcomes.
The Hidden Quality Cost
The productivity headline hides a quality cost that is only becoming visible as AI-generated code accumulates in production codebases. GitClear's code quality analysis found that code churn rate has risen from 3.1% in 2020 to 5.7% in 2025—code being rewritten within two weeks of being committed. AI-coauthored code is the primary driver of this trend.
48% of AI-generated code has potential security vulnerabilities according to security analysis studies. This is not because the models are writing actively malicious code—it's because the models optimize for passing tests and producing plausible-looking code, not for security properties that require broader context to reason about. An LLM doesn't know your threat model. It doesn't know that input X comes from an untrusted source. It doesn't know that function Y is called in a privilege-escalated context.
Google has disclosed that 25–30% of new code at the company is AI-generated. At that scale, the quality cost is an architectural concern, not an individual developer concern. When 30% of your new code is generated by a system with known vulnerability patterns, you need systematic controls, not code review guidelines.
The 20M Copilot Users Problem
With 20 million GitHub Copilot users and a $3–3.5 billion market for AI coding tools in 2025, AI coding assistance is no longer optional infrastructure for most engineering organizations. The question is not whether to use it—it is how to use it in a way that captures the productivity gains without accumulating hidden technical debt.
84% of developers use AI tools and 51% use them daily per the JetBrains Developer Survey. DX research shows that developer experience improvements from AI tools are real and measurable—reduced cognitive load on routine tasks, faster onboarding to unfamiliar codebases, reduced context-switching between documentation and editor. These are legitimate quality-of-work improvements that affect retention, not just velocity.
The Enterprise SDLC Integration Architecture
|
SDLC Phase |
AI Tool Role |
Quality Controls Required |
Human Review Scope |
|
Design / architecture |
Reference only |
Architect review mandatory |
Full — AI not authoritative |
|
Specification writing |
Draft assistance |
PM + engineering review |
Full — correctness verification |
|
Implementation |
Code generation |
Security scan + code review |
Diff review + security flag triage |
|
Test writing |
Test generation |
Coverage + mutation testing |
Coverage gap review |
|
Code review |
Reviewer assist |
Human review not replaced |
Human reviews all AI flags |
|
Documentation |
Draft generation |
Technical accuracy review |
Full — accuracy verification |
|
Debugging |
Hypothesis generation |
Engineer validates root cause |
Engineer owns diagnosis |
Security Controls for AI-Generated Code
Standard SAST tools are necessary but not sufficient for AI-generated code. The vulnerability patterns in LLM-generated code differ from the patterns in human-written code, and existing rules engines were calibrated on human-written code distributions. You need:
Measuring What Actually Matters
Most engineering teams measure AI coding tool adoption by acceptance rate—the percentage of AI suggestions accepted. This metric is actively misleading. A high acceptance rate combined with high churn rate means developers are accepting AI suggestions and then rewriting them. You want the velocity and quality metrics to move together, not in opposite directions.
Better metrics: change failure rate (what % of deploys cause incidents), time to restore service after AI-assisted code deploys vs. human-written code deploys, and security vulnerability density per thousand lines of AI-generated vs. human-written code. These metrics reveal the true production impact of AI coding tools and are largely absent from vendor-published research.
# CI pipeline controls for AI-assisted codebases security_gates: - semgrep --config=auto # SAST with AI-specific rules - bandit -r src/ # Python security analysis - trivy fs . # Dependency vulnerability scan - gitleaks detect # Secret detection (AI models leak secrets) quality_gates: - pytest --cov=src --cov-fail-under=80 - mutmut run # Mutation testing (validates test quality) - radon cc src/ -a -nb # Cyclomatic complexity review_requirements: ai_assisted_prs: min_reviewers: 2 # One additional reviewer for AI PRs security_review: required_for_auth_crypto_network churn_alert: flag_if_modified_within_14_days
Production Readiness Checklist
☑ AI coding tool usage policy documented with approved tools list
☑ Security scan pipeline includes AI-specific vulnerability rules (Semgrep, Bandit)
☑ Secret detection (Gitleaks or equivalent) in pre-commit and CI
☑ Code churn rate monitored per team and flagged when exceeding 5% threshold
☑ Mutation testing deployed to validate quality of AI-generated test suites
☑ AI-assisted PRs labeled and tracked for quality metrics disaggregation
☑ Security review required for AI-generated auth, crypto, and network code
☑ Developer training covers METR paradox: task type selection for AI assistance
☑ Change failure rate tracked separately for AI-assisted vs. human-written deploys
What I Would Build Differently
Every engineering organization that has deployed AI coding tools at scale has discovered the quality cost the hard way—through elevated churn, security findings, or production incidents. The ones that recovered fastest are the ones that instrumented the quality metrics from day one rather than adding them after the first incident.
Treat AI coding tool adoption the same way you would treat any other infrastructure change: establish baselines before rollout, measure the metrics that matter (not the metrics vendors report), and build the quality controls into the SDLC before the tools are widely adopted.
References
1. GitHub Copilot Research
2. DX Developer Survey
3. JetBrains Developer Survey 2025
4. METR AI Tools Study
5. Panto AI Coding Assistant Statistics
6. GitClear Code Quality Report
Comments (0)
Join the conversation!