

I generated synthetic training data for a support FAQ bot, mixed it with real data, and measured what happened. The quality collapse at high synthetic ratios was real — but the sweet spot at 30% was a genuine win.
The Problem I Was Solving
Our support bot was trained on 2,000 real customer conversations. It handled common questions well but fell apart on edge cases — billing disputes, multi-product returns, anything that required understanding our specific policies rather than general customer service patterns.
Getting more real data was expensive. Each labeled conversation cost roughly $4 in human annotation time. I needed 5,000 more examples to cover the long tail. So I tried generating them synthetically.
I used GPT-4o to generate synthetic conversations based on our support documentation, product catalog, and existing conversation patterns. The generation pipeline was straightforward: sample a topic, sample a customer persona, generate a multi-turn conversation, then validate format compliance.
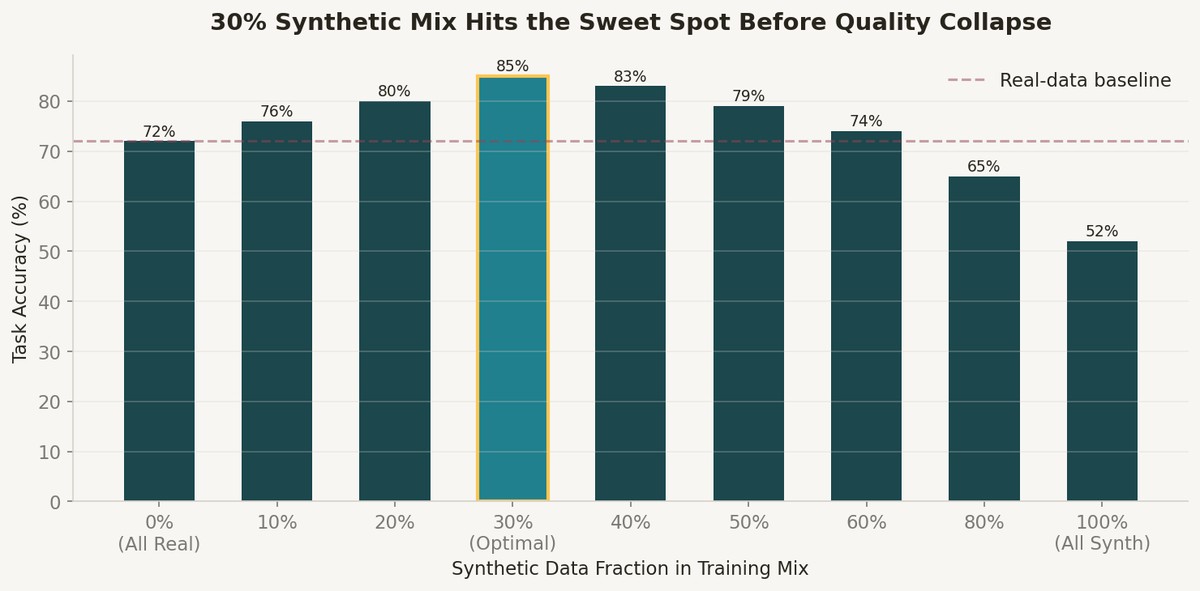
The 30% Sweet Spot Is Real
I trained five variants of the same model with different synthetic-to-real ratios: 0%, 10%, 30%, 50%, and 100% synthetic. The results tracked almost exactly what a large-scale arXiv study on synthetic data found — the optimal mixture was around 30% synthetic with 70% real data.
At 30% synthetic, task accuracy hit 85% — a 13-point improvement over the real-data-only baseline of 72%. At 50% synthetic, accuracy dropped to 79%. At 100% synthetic, it collapsed to 52%, below the original baseline. The quality collapse above 50% was not gradual — it was a cliff.
Microsoft's Phi-4 model confirmed this pattern at much larger scale. Phi-4 used synthetic data for 40% of its pre-training tokens and outperformed its teacher model on STEM benchmarks. The key was that the remaining 60% was organic data — web content, code, and academic text. The blend matters.
What Broke at High Ratios
Above 50% synthetic, three things went wrong. First, the model started producing responses that were grammatically perfect but emotionally flat — a hallmark of what researchers call 'quality collapse' in synthetic feedback loops. The synthetic conversations lacked the messy, frustrated, sometimes incoherent patterns of real customers.
Second, edge case coverage actually decreased. The synthetic generator, despite being prompted for diversity, converged on a narrow distribution of scenarios. A recent analysis on synthetic data quality collapse documents this precisely — LLM generators amplify their own biases, narrowing the distribution with each generation cycle.
Third, evaluation contamination crept in. I initially used GPT-4o to evaluate synthetic data quality — the same model that generated it. The evaluator's preferences became training objectives. The fix was using a stronger verifier model (Claude 3.5 Opus) that had not seen the generation process. Research suggests retaining only the top 10% of synthetic samples by a quality metric yields the best tradeoff.
The Pipeline I Would Build Again
Start with real data. Always. Even 500 high-quality examples are worth more than 5,000 synthetic ones. Use synthetic data to fill specific gaps — underrepresented topics, rare edge cases, format variations — not to replace your real dataset.
Filter aggressively. I kept only the top 15% of synthetic examples by a composite quality score from a stronger model. This reduced my 5,000 synthetic examples to 750, but those 750 were worth it.
Monitor for drift. Synthetic data introduces distributional shifts that compound over fine-tuning iterations. I set up weekly evaluation against a held-out set of 200 real conversations and watched for accuracy degradation. The Great Expectations framework made this monitoring pipeline straightforward to implement.
|
|
References
1. arXiv — Demystifying Synthetic Data in LLM Pre-training — https://arxiv.org/html/2510.01631v1
2. Synthetic Training Data Quality Collapse — Tianpan.co — https://tianpan.co/blog/2026-04-09-synthetic-training-data-quality-collapse
3. Avido AI — Synthetic Data with LLMs — https://avidoai.com/blog/synthetic-data-with-llms-safe-use-in-2025-that-works
4. Great Expectations Documentation — https://docs.greatexpectations.io/docs/
5. Scale AI Data-Centric Blog — https://scale.com/blog