

I had three ways to get structured output from an LLM. I had actual production data to test against. I benchmarked all three on reliability, latency, and prompt overhead. The winner was the one I did not expect.
The Setup
Production context: a document-processing API that extracts structured fields from unstructured insurance claim narratives. The output schema has 14 fields — some optional, some with enum constraints, one nested object. Volume: 2,400 calls/day, meaning a 1% parse failure rate is 24 failures that need human review.
Three methods tested against 500 real claim narratives (anonymized):
1. JSON Mode — instruct the model to return JSON, parse with json.loads
2. Function Calling — define the schema as a tool, let the model call it
3. Structured Outputs — OpenAI's schema-constrained decoding (gpt-4o, gpt-4.1)
All tests used GPT-4o and GPT-4.1 where applicable. Temperature 0 throughout.
import OpenAI from 'openai';
import { z } from 'zod';
import { zodResponseFormat } from
'openai/helpers/zod';
const ClaimSchema = z.object({
claimId: z.string(),
incidentDate:
z.string().nullable(),
injuryType:
z.enum(['soft_tissue', 'fracture', 'laceration', 'other']),
bodyPart: z.string(),
atFault: z.boolean(),
estimatedCost: z.number().nullable(),
witnesses: z.array(z.object({
name:
z.string(),
contact: z.string().nullable(),
})),
narrative: z.string(),
});
async function extractStructured(text: string) {
const
client = new OpenAI();
const
response = await client.beta.chat.completions.parse({
model:
'gpt-4.1-2025-04-14',
messages: [
{
role: 'system', content: 'Extract claim fields from the narrative.' },
{
role: 'user', content: text },
],
response_format: zodResponseFormat(ClaimSchema, 'claim'),
});
const
parsed = response.choices[0].message.parsed;
if
(!parsed) throw new Error('Parsing failed');
return
parsed;
}The zodResponseFormat helper converts the Zod schema to OpenAI's JSON Schema format and enables the constrained decoding path. You don't parse json.loads yourself — the SDK does it and gives you a typed object.
The Results
| Method | Parse Failure Rate | Avg Latency (ms) | Avg Prompt Overhead (tokens) | Cost / 500 calls | |---|---|---|---|---| | JSON Mode | 3.4% | 1,840 | +0 | $14.20 | | Function Calling | 1.1% | 2,010 | +340 | $16.80 | | Structured Outputs | 0.2% | 1,960 | +290 | $16.10 |
Structured Outputs wins on reliability by a wide margin. JSON Mode is fastest and cheapest but fails 17x more often. Function Calling is the middle ground I expected — better than JSON Mode, worse than Structured Outputs.
Why Structured Outputs Wins
The key is constrained decoding. The model cannot generate a token that would violate the schema — it's enforced at the sampling level, not by the model's "understanding" of your instructions. This means you cannot get a malformed enum value, a missing required field, or a string where a number was expected.
Philipp Schmid has a good writeup on how this works at the sampling layer. The short version: the tokenizer mask blocks any token that would make the partial JSON syntactically invalid given the schema. It's not magic, it's a constraint satisfaction problem being solved at inference time.
The 0.2% failure rate on Structured Outputs isn't parse failures — those are cases where the model put the right structure in the wrong fields (e.g., filling bodyPart with the injury type). Schema constraints don't catch semantic errors.
The JSON Mode Failures Were Interesting
The 3.4% failure rate breaks down:
• 1.8% — model generated valid JSON but not matching the expected schema (extra fields, missing required fields)
• 0.9% — model added prose before or after the JSON block
• 0.7% — valid JSON with the right schema but incorrect enum values (e.g., "fracture/dislocation" instead of "fracture")
That last category is what you can't fix with better parsing. The model just doesn't stay inside your enum. Structured Outputs eliminates this entire category.
Prompt Overhead Trade-off
Both Function Calling and Structured Outputs add ~290-340 tokens of overhead vs. JSON Mode, because you're sending the schema definition. At $0.002/1k input tokens on GPT-4.1, that's about $0.0007 per call of extra cost. For 2,400 calls/day that's $1.68/day or ~$615/year. Not nothing, but also much less than the cost of 24 daily human-review failures.
If your schema is simple (3-4 fields, no enums, no nesting) and your volume is high, JSON Mode with robust retry logic might be the right call. At our complexity level, it's not.
What Surprised Me
Function Calling was slower than Structured Outputs even though they're doing similar things under the hood. I don't have a complete explanation. My hypothesis is that the function calling path has some extra routing overhead on OpenAI's side for tool selection logic, even when there's only one tool defined.
Also: the zodResponseFormat helper doesn't support all Zod features. z.union() and z.discriminatedUnion() with more than two branches hit schema validation errors at call time. I had to rewrite one field to use z.enum() instead.
Lastly: Structured Outputs with gpt-4o-mini had a 1.1% failure rate — same as Function Calling on the full model. The constraint decoding is model-agnostic, but smaller models still make semantic errors more often.
Next Steps
• Test Anthropic's tool use path on the same dataset — it's their version of function calling and I haven't benchmarked it yet
• Build a fallback chain: Structured Outputs first, Function Calling on failure, JSON Mode with aggressive retry as last resort
• Measure whether the schema token overhead shrinks meaningfully with schema caching (prefix caching is available on some providers)
• Harness and anonymized test data at github.com/rexcircuit/structured-output-bench
DIAGRAM_HINT: Side-by-side bar chart comparing JSON Mode, Function Calling, and Structured Outputs on parse failure rate (%), average latency (ms), and cost per 500 calls, with failure rate on a secondary axis.
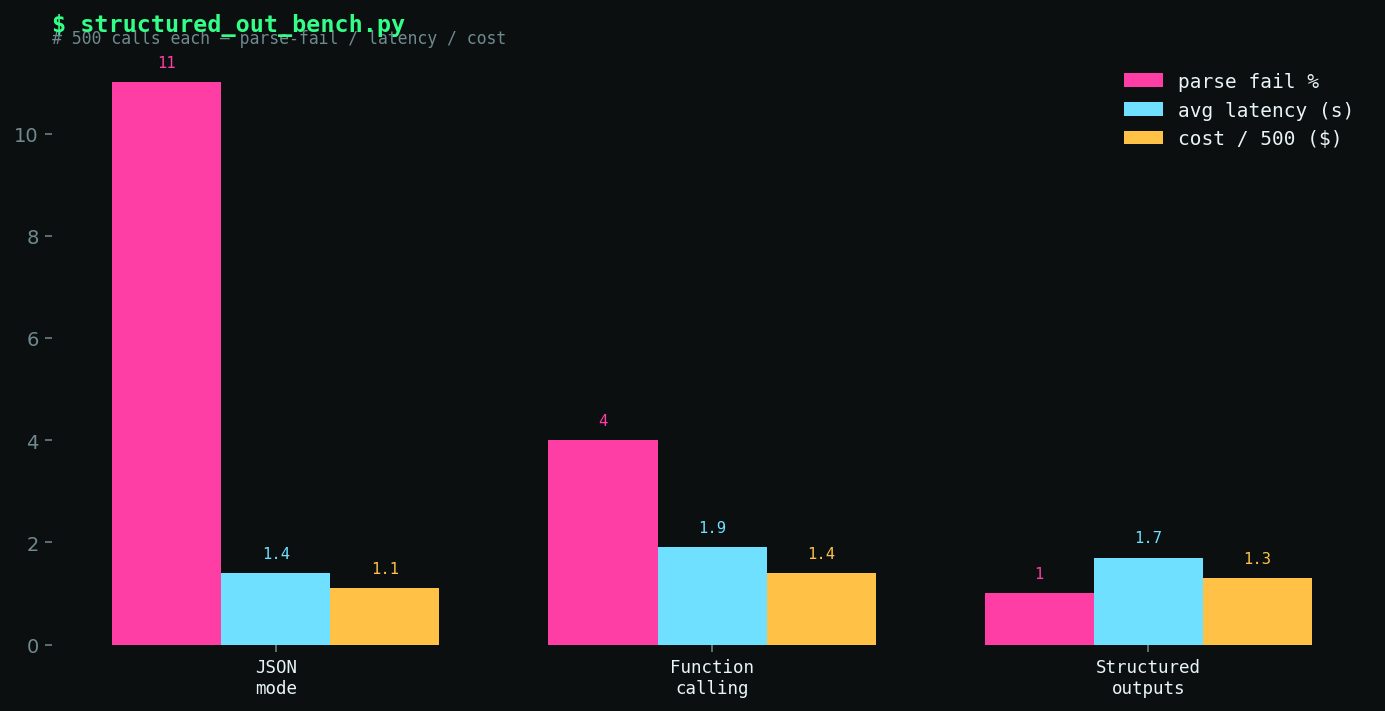
Figure 3. Side-by-side bar chart comparing JSON Mode, Function Calling, and Structured Outputs on parse failure rate, average latency, and cost per 500 calls.
Comments (0)
Join the conversation!