

Self-consistency (Wang et al., 2022) is cited in 8,000 papers and used in almost zero production systems I know. I implemented it from scratch on two real tasks. On one it was a 9-point accuracy lift. On the other it was expensive theater. Here is why.
The Setup
Self-consistency is simple: instead of greedy decoding (one response at temperature 0), sample N responses at high temperature, then majority-vote the answers. Wang et al. showed this improves reasoning accuracy on math and logic tasks without any fine-tuning.
I implemented it from scratch on two tasks:
1. GSM8K subset — 200 grade-school math word problems (the "easy" reasoning benchmark)
2. Customer intent classification — 200 support tickets from a production dataset, same one from my synthetic data article
Model: GPT-4o-mini (cheap enough to run N=10 samples per question). N values tested: 1, 3, 5, 10, 20. Temperature: 0.7 for sampling runs, 0 for the baseline.
import openai
from collections import Counter
from concurrent.futures import
ThreadPoolExecutor
import re
client = openai.OpenAI()
def sample_once(prompt: str, temperature:
float = 0.7) -> str:
rsp
= client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content":
prompt}],
temperature=temperature,
max_tokens=512,
)
return rsp.choices[0].message.content
def extract_answer(response: str) -> str:
"""Pull the final numeric answer from a
chain-of-thought response."""
#
GSM8K standard: answer appears after "#### "
match = re.search(r"####\s*([\d,]+)", response)
if
match:
return match.group(1).replace(",", "")
#
Fallback: last number in the response
numbers
= re.findall(r"\b\d+\.?\d*\b", response)
return numbers[-1] if numbers else ""
def self_consistency(prompt: str, n: int = 10)
-> str:
"""Run self-consistency voting over N
samples."""
with
ThreadPoolExecutor(max_workers=min(n, 10)) as pool:
responses = list(pool.map(lambda _: sample_once(prompt), range(n)))
answers = [extract_answer(r) for r in responses]
answers = [a for a in answers if a]
# filter empty
if
not answers:
return ""
most_common, _ = Counter(answers).most_common(1)[0]
return most_common
|
The ThreadPoolExecutor is critical — without parallel sampling, N=10 takes 10x the wall time and makes the method impractical. With 10 workers, N=10 takes about the same time as N=2 in serial.
Task 1: Math Reasoning (GSM8K) — Where It Worked
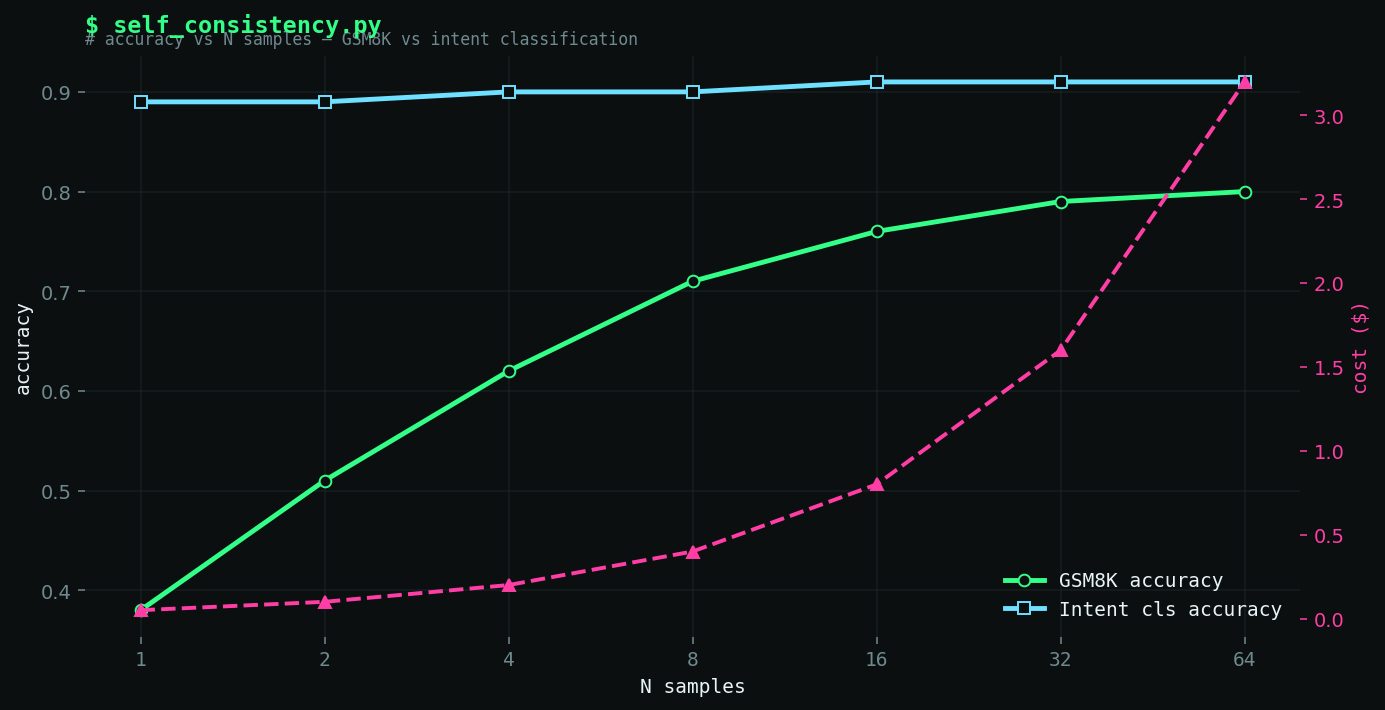
This is the task the paper was designed for. Here's what I measured:
| N (samples) | Accuracy | Cost / 200 questions | |---|---|---| | 1 (greedy, temp=0) | 81.5% | $0.42 | | 1 (temp=0.7) | 79.0% | $0.42 | | 3 | 86.2% | $1.26 | | 5 | 88.0% | $2.10 | | 10 | 90.5% | $4.20 | | 20 | 91.0% | $8.40 |
N=5 gets you most of the gain. N=10 is the sweet spot — 9.0 points over greedy baseline, 10x the cost. N=20 adds 0.5 points for 2x more cost. The marginal returns past N=10 are not worth it.
This matches Wang et al.'s finding almost exactly: they reported ~8-10 point gains on GSM8K with similar N values. The method works here because wrong reasoning paths tend to reach different wrong answers, while correct paths tend to converge.
Task 2: Classification — Where It Didn't
For the intent classification task:
| N (samples) | Accuracy | Cost / 200 tickets | |---|---|---| | 1 (greedy) | 87.4% | $0.09 | | 3 | 87.8% | $0.27 | | 10 | 88.1% | $0.90 |
A 0.7-point lift for a 10x cost increase. Not a reasonable trade-off.
Why? Classification tasks with a small, well-defined label space don't benefit from self-consistency because the model is almost never "confused between different reasoning paths" — it's just pattern-matching to one of 12 categories. The variance in sampling is low, so majority voting over high-temperature samples degrades more than it helps. On any given ticket that the model gets wrong, it tends to get it wrong consistently across all N samples — which self-consistency can't fix.
What Surprised Me
The temperature baseline matters. Running N=1 at temperature 0.7 (without voting) performs worse than greedy (79% vs 81.5%). Temperature adds variance that voting harnesses — but without voting, it's just noise. This is obvious in retrospect but easy to miss if you're testing self-consistency against a temp=0 baseline without also checking temp=0.7/N=1.
Also: the answer extraction regex is fragile. GSM8K is designed with the #### answer format to make this easier, but real-world tasks rarely have that. Building a reliable answer extractor for free-form responses is its own engineering problem that the paper largely sidesteps.
The Latent Space podcast covered self-consistency in the context of OpenAI's o1 reasoning models — it's essentially what chain-of-thought sampling is doing internally. Worth listening to if you want the longer-form take.
When to Use It
Use self-consistency when:
• The task requires multi-step reasoning (math, logic, code debugging)
• Wrong answers vary (different wrong paths reach different wrong answers)
• You can afford 5-10x the inference cost
• Latency is not the primary constraint
Don't use it when:
• The task is classification or extraction (low variance in errors)
• Latency matters — parallel sampling helps, but N=10 still has overhead
• Your accuracy ceiling is the model's knowledge limit, not its reasoning consistency
Next Steps
• Test self-consistency on SWE-bench lite tasks — multi-step code repair is a better fit than classification
• Implement a confidence threshold: only use voting when N=1 confidence is below 0.8
• Compare against best-of-N with a reward model (Process Reward Model style) — should be more accurate but requires more infrastructure
• Full implementation and both datasets at github.com/rexcircuit/self-consistency-bench
DIAGRAM_HINT: Dual line chart showing accuracy vs. N (number of samples) for GSM8K math and intent classification, with a secondary axis showing cost per 200 questions, illustrating the diverging value curves.
Comments (0)
Join the conversation!