

I rebuilt a workflow I had been running manually for six months as a three-agent LangGraph system. Two of the three agents worked on the first try. The third one is a story. Here is the build log.
What I Built
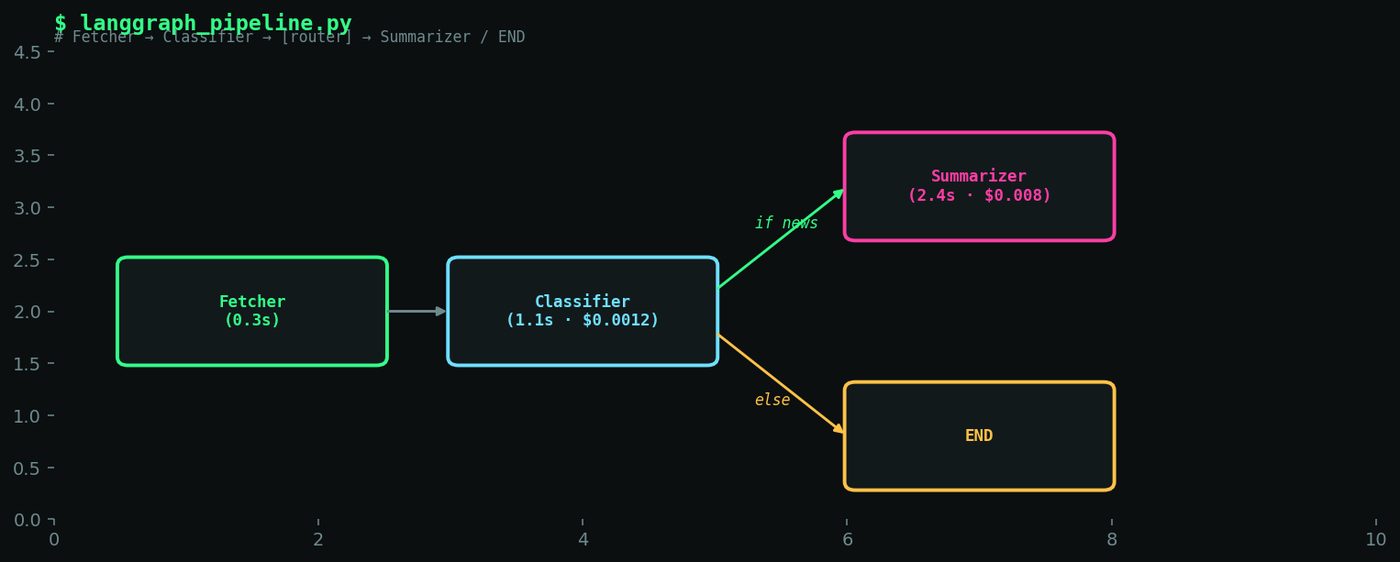
Environment: Python 3.12, LangGraph 0.2.x, Claude 3.7 Sonnet as the backbone model, PostgreSQL 16 for state persistence, deployed on a $12/month Hetzner VPS. The workflow I was automating: weekly competitive intelligence — pull RSS feeds from 20 competitor blogs, classify each post by topic, summarize the relevant ones, and draft a Slack digest.
Three agents:
1. Fetcher — hits RSS feeds, deduplicates, stores raw entries
2. Classifier — decides which entries are relevant (vs. fluff marketing posts)
3. Summarizer — generates the Slack digest from classified entries
I budgeted a weekend and got it done in one day and most of a second. Total LLM spend during development: $3.80.
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.postgres import PostgresSaver
from typing import TypedDict, Annotated
import operator
class IntelState(TypedDict):
raw_entries: list[dict]
classified: list[dict]
digest: str
errors: Annotated[list[str], operator.add] # append-only
def build_graph(db_url: str) -> StateGraph:
checkpointer = PostgresSaver.from_conn_string(db_url)
graph
= StateGraph(IntelState)
graph.add_node("fetcher",
fetcher_node)
graph.add_node("classifier", classifier_node)
graph.add_node("summarizer", summarizer_node)
graph.set_entry_point("fetcher")
graph.add_edge("fetcher", "classifier")
graph.add_conditional_edges(
"classifier",
route_after_classify,
{"enough": "summarizer", "too_few": END},
)
graph.add_edge("summarizer", END)
return
graph.compile(checkpointer=checkpointer)
def route_after_classify(state: IntelState)
-> str:
relevant = [e for e in state["classified"] if
e["relevant"]]
return
"enough" if len(relevant) >= 3 else "too_few"The Annotated[list, operator.add] trick for the error accumulator came from the LangGraph docs — it means each node can append errors without overwriting the whole list. Took me 20 minutes to find, worth knowing.
The Fetcher and Classifier: First-Try Wins
Fetcher was boring in the best way. Point it at an OPML file, get entries, deduplicate by GUID. Runs in ~8 seconds for 20 feeds. No LLM involved, pure RSS parsing with feedparser.
Classifier was trickier but still worked first try. I gave Claude a system prompt with a rubric: "Relevant = technical posts about product changes, API updates, or architecture decisions. Not relevant = job postings, generic thought-leadership, event announcements." Tested it against 50 hand-labelled entries from the past month — 94% agreement with my labels. Good enough.
What made the classifier reliable: the rubric was specific. No fuzzy language like "interesting" or "important." The prompt said exactly what counts. That matters a lot and it's something Swyx has talked about on Latent Space — most classification prompt failures are rubric failures, not model failures.
The Summarizer: The Story
The Summarizer worked fine in isolation. In the graph, it kept producing summaries that were too short — four bullet points when I wanted eight to twelve. I spent three hours debugging before I found the problem.
The issue: I was passing the classified entries to the Summarizer via the graph state, and the state serialization was silently truncating the body text of each entry at 512 characters because of a default field validator I had added early in development and forgotten about. The Summarizer saw truncated inputs and produced proportionally short outputs. The model was doing exactly the right thing with bad data.
The fix was a one-liner — remove the validator. The lesson is that LangGraph state is a typed dictionary and every field you add to it has implications for what downstream nodes see. Log your intermediate state during development. I now add a debug_node between every pair of nodes when developing locally.
Checkpoint Persistence Is Worth the Setup
The PostgresSaver checkpointer adds maybe 30 minutes of setup — create a table, pass the connection string, done. What you get is that every graph run is resumable. When the Fetcher hits a rate-limited RSS feed and throws, the graph stops, stores state, and you can resume from that exact point. Without this, a failure means reprocessing all 20 feeds from scratch.
For a weekend project this felt like overkill. After the fourth time I had to debug mid-run failures, it felt like the most important decision I made.
Performance Numbers
| Stage | Avg Runtime | LLM Calls | Cost / Run | |---|---|---|---| | Fetcher | 8.2 s | 0 | $0.00 | | Classifier (20 entries) | 34.1 s | 20 | $0.18 | | Summarizer | 12.4 s | 1 | $0.04 | | Total | 54.7 s | 21 | $0.22 |
That $0.22/run is $0.88/week or about $46/year. Cheaper than the one hour of manual work it was replacing every week.
What Broke
Aside from the serialization bug: the conditional routing. LangGraph's add_conditional_edges is clean when the condition is simple. Mine had an edge case — some weeks there are exactly two relevant entries, neither enough for a real digest nor few enough to skip cleanly. I ended up needing a third route I hadn't designed for. The graph handles it now, but the initial design assumed a clean binary.
Also: the Fetcher occasionally returns entries with the same title but different GUIDs (some CMS platforms regenerate GUIDs on edits). The deduplication by GUID fails there. I now deduplicate on a hash of (title + truncated body) as well.
Next Steps
• Add a human-in-the-loop node that pauses for approval before the Slack post goes out
• Swap Claude for a cheaper local model on the classifier stage — it's a binary classification, Phi-3 mini can probably handle it
• Extend to 50 sources and measure whether per-run cost scales linearly
• Full code at github.com/rexcircuit/langgraph-intel-bot
DIAGRAM_HINT: Flow diagram showing three-node LangGraph DAG (Fetcher → Classifier → conditional router → Summarizer or END) with annotated average runtime and cost per stage.
Comments (0)
Join the conversation!