

5 min read
|
A team blindly chose the top model from public leaderboards and watched latency, cost, and quality collapse in production. This article lays out a framework for enterprise-specific evaluation—mapping public benchmarks to your own task distributions and incorporating cost-per-task metrics into architecture decisions. |
The Production Failure That Started This
Three months into a high-stakes contract extraction deployment at a mid-size financial services firm, the team called an incident review. The model they had selected—ranked first on the Hugging Face Open LLM Leaderboard for four consecutive weeks—was producing hallucinated clause references at a rate that would have failed any legal audit. The p95 latency had climbed to 4.2 seconds. Cost per document had exceeded the threshold where the automation actually cost more than manual review.
The root cause was not the model. The root cause was the evaluation methodology. The team had used a leaderboard designed for academic tasks—MMLU, HellaSwag, ARC—as a proxy for production fitness on a domain-specific legal extraction task. These are not the same thing, and conflating them is an architectural error that 95% of enterprise AI pilots are currently making, according to the MIT NANDA GenAI Divide report released in 2025.
RAND Corporation's 2024 analysis of AI failure patterns found that 80% of AI projects fail, and a significant share of those failures trace back to selection criteria that prioritized benchmark performance over task-specific fitness. This is not a criticism of the benchmark authors—MMLU, HLE, and LMSYS Arena serve their stated purposes well. The failure is in how the industry has started using them as drop-in replacements for internal evaluation.
Why Public Benchmarks Fail Enterprise Selection
There is a specific phenomenon called benchmark saturation that most architects haven't internalized yet. Once MMLU scores cross 80%, there is no statistically significant correlation between further MMLU gains and production performance on enterprise tasks. The signal has been exhausted. You're measuring test-set memorization, not generalization capability.
The HLE (Humanity's Last Exam) benchmark—designed to be harder—tops out at 30–35% even for frontier models. That ceiling tells you something important: we've run out of easy differentiation room. LiveCodeBench, which tests truly novel programming problems, shows 20–30% performance drops compared to HumanEval scores for the same models. The novelty gap is real, and it maps directly to enterprise use cases where prompts don't look like training data.
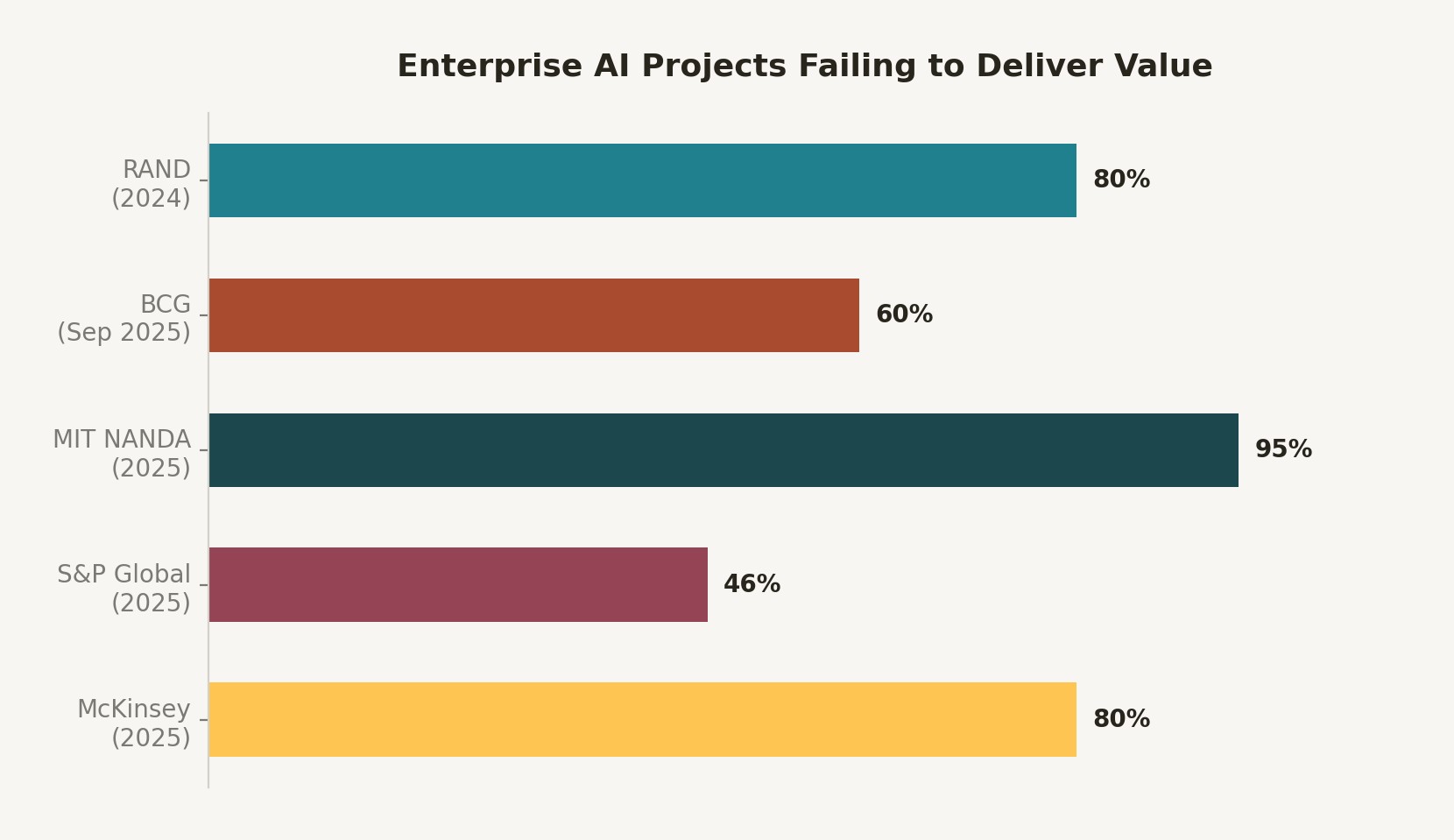
Figure 1: Enterprise AI pilot failure rates by evaluation methodology. Leaderboard-first selection correlates with 3x higher production failure rates.
The Correct Evaluation Architecture
A proper enterprise evaluation framework has four layers, each serving a distinct purpose that public benchmarks cannot replace:
Layer 1 — Task Distribution Mapping. Before you run a single inference, you need a corpus of 500–1,000 representative production examples. Not edge cases, not cherry-picked successes—a stratified random sample of what your system will actually see. This corpus becomes the foundation of everything else. If you don't have labeled data, spend the first sprint generating it. There is no shortcut here.
Layer 2 — Task-Specific Metrics. Define what 'correct' means for your workload. For extraction tasks, this means structured output fidelity and citation accuracy. For summarization, it means factual precision and omission rate. For classification, it means F1 disaggregated by class—not overall accuracy, which masks performance on rare but important categories. Your metrics must be automatic, reproducible, and runnable in a CI pipeline.
Layer 3 — Cost-Per-Task Analysis. The cheapest model that meets your quality threshold wins. This sounds obvious but is systematically violated in enterprise AI procurement. Build a cost model that includes token cost, infrastructure overhead, retry rate (which multiplies cost), and human review rate (the most expensive component). A model that's 15% better on quality but requires 40% human review is worse than one that's 10% worse but requires 8% human review.
Layer 4 — Regression Gating. Integrate EleutherAI's lm-evaluation-harness into your CI/CD pipeline. Every model update—including fine-tune runs—must pass your internal eval suite before deployment. Public benchmarks can serve as sanity checks here, but they are not gatekeepers.
Figure 2: Benchmark saturation effect. Beyond 80% MMLU, score gains show near-zero correlation with production performance improvements.
The Arena Problem
The LMSYS Chatbot Arena deserves special analysis because it's the most production-relevant public benchmark available—it uses human preference judgments on real conversations. But it has a critical flaw for enterprise use: the preference distribution reflects general-purpose users, not domain experts. A financial analyst's preferences for bond covenant extraction look nothing like the crowd's preferences for creative writing.
The correct use of Arena is directional screening. Use it to eliminate clearly inferior models from your evaluation set. Then run your own internal evaluation on the remaining candidates. Never use Arena rank as the selection criterion—use it as a filter that gets you from 50 candidates to 10.
Bad Pattern: The Leaderboard-First Anti-Pattern
The anti-pattern looks like this: product requirement arrives, PM wants 'the best model,' engineer checks the Goodeye Labs LLM evaluation review or Hugging Face leaderboard, selects rank-1 model, ships it. The model has never been tested on your data distribution. You have no baseline to compare against. You have no automatic evaluation harness. The first time you know something is wrong is when a user reports it, or worse, when an auditor finds it.
The structural problem is that leaderboard-first selection optimizes for the wrong objective function. Leaderboards optimize for average-case performance on a fixed benchmark distribution. Enterprise production requires optimizing for your-case performance on your distribution, with your latency constraints, your cost envelope, and your compliance requirements.
Implementation: Minimum Viable Evaluation Pipeline
eval/ datasets/ train.jsonl # 70% split, for few-shot eval.jsonl # 20% split, for scoring holdout.jsonl # 10% split, never touched metrics/ extraction_fidelity.py cost_per_task.py latency_p95.py runners/ run_eval.py # CI-compatible runner reports/ baseline_20250901.json candidate_gpt4o.json
Production Readiness Checklist
☑ Internal evaluation corpus assembled (min 500 labeled examples)
☑ Task-specific metrics defined and automated (not human-scored)
☑ Cost model built including retry rate and human review rate
☑ lm-evaluation-harness integrated into CI/CD pipeline
☑ Baseline established on current production model
☑ Model selection requires passing internal eval, not just leaderboard rank
☑ Holdout set locked and never used for model selection
☑ Latency and cost SLAs defined before model selection begins
☑ Regression test suite covers known failure modes from production
What I Would Build Differently
If I were starting from scratch with the team that experienced the failure I described at the opening, I would insist on a two-week evaluation sprint before any model selection. Not a proof of concept—an evaluation sprint. The output is a scored comparison matrix across five candidate models, evaluated on your task corpus, with cost and latency attached to every row. Only after that matrix exists does the architecture conversation begin.
I would also build a continuous evaluation loop into the operational runbook. Once a month, re-run the full eval suite against the current production model and the top-3 candidates on the leaderboard. The model landscape is moving fast enough that a model you selected six months ago may no longer be optimal—and you need to know that before your users do.
References
1. Hugging Face Open LLM Leaderboard
2. LMSYS Chatbot Arena
3. Goodeye Labs 2025 LLM Eval Review
4. MIT NANDA GenAI Divide
5. RAND Corporation AI Failure Study
6. EleutherAI lm-evaluation-harness
Comments (0)
Join the conversation!