

5 min read
|
The old framing—LangChain for workflows, LlamaIndex for retrieval—is outdated. Both frameworks now converge on overlapping territory, and this article provides a production-grade decision framework for choosing, migrating, or running hybrid stacks. |
The Framework Convergence Problem
Two years ago, the decision was easy: LangChain for chaining and workflow orchestration, LlamaIndex for document indexing and retrieval. The boundary was clear. Teams could make a quick, defensible choice and move on. That boundary no longer exists. LlamaIndex has built a full agentic workflow layer. LangChain has built LangGraph for production workflow control and dramatically improved its RAG tooling. Both frameworks now offer substantially similar capabilities, and the decision is no longer obvious.
This convergence has created a specific enterprise problem: 70% of regulated enterprises are rebuilding their AI agent stacks every three months. Some of that churn is framework migration—teams that made an early bet on one framework discovering that it doesn't cover their evolving production requirements and paying the migration cost repeatedly.
LangChain has 119,000 GitHub stars. LlamaIndex has 44,000. Star counts are not architecture guidance—but they do reflect ecosystem size, which matters for hiring, community support, and third-party integrations. Neither number should be the deciding factor, but both are worth knowing.
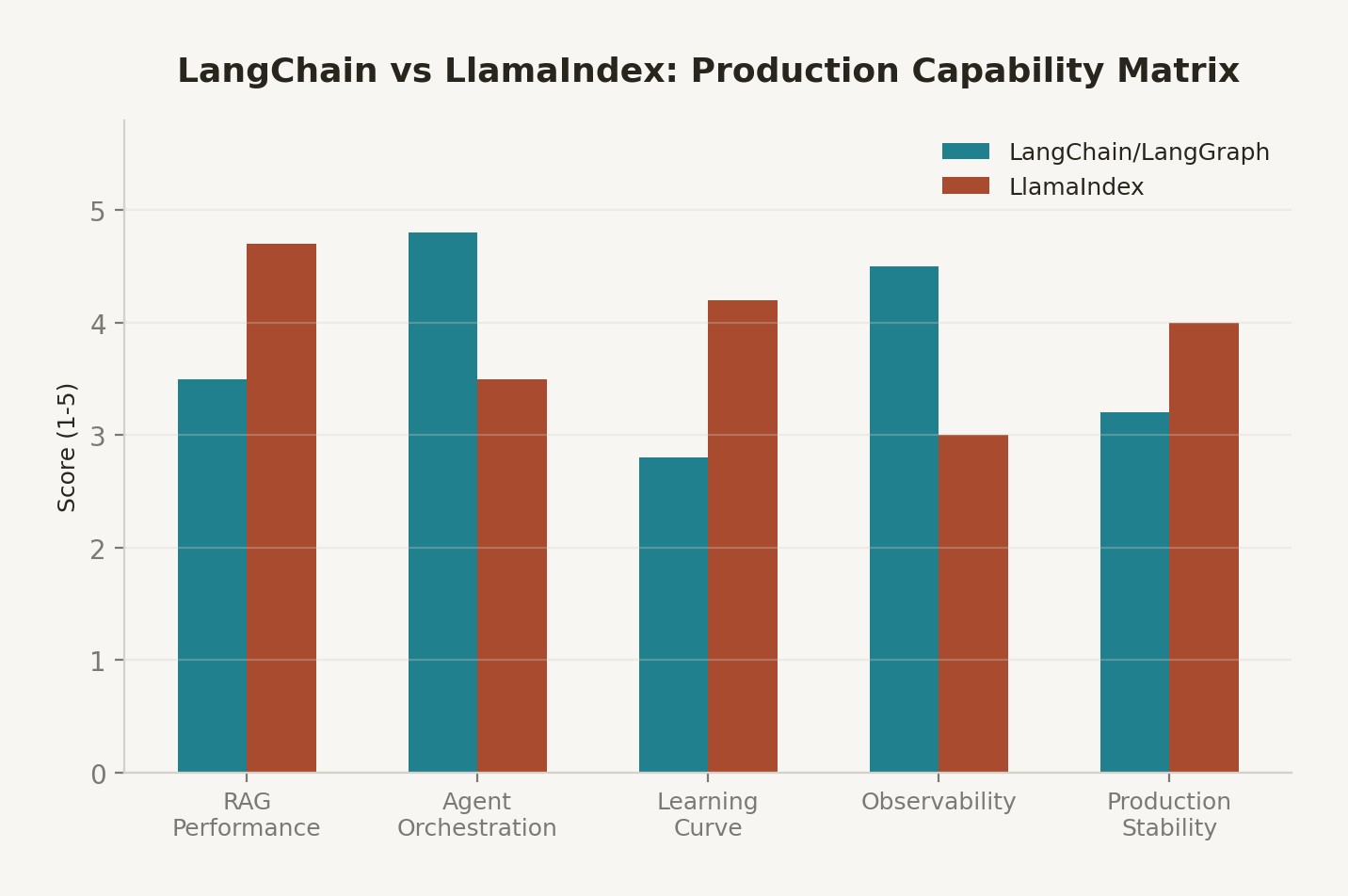
Figure 1: LangChain vs. LlamaIndex feature coverage comparison across key production RAG capabilities. Convergence is visible across most dimensions.
Where Each Framework Actually Wins
Benchmarking conducted across multiple production systems shows that LlamaIndex achieves 35% better retrieval accuracy and 40% faster retrieval throughput in document-heavy workloads with complex hierarchical structures. This is the native advantage of a system built from the ground up for indexing. The RouterQueryEngine, SubQuestionQueryEngine, and recursive retrieval patterns are more mature in LlamaIndex than in LangChain's retrieval layer.
LangChain's native advantage is workflow orchestration complexity. LangGraph—introduced for production workflow control—provides a genuinely superior model for stateful, branching agent workflows compared to LlamaIndex's workflow layer. If your use case involves multi-agent systems, conditional routing, human-in-the-loop approval steps, and complex state management, LangGraph's explicit graph model is easier to reason about, test, and debug than LlamaIndex's pipeline abstractions.
The Migration Decision Matrix
|
Requirement |
LangChain/LangGraph |
LlamaIndex |
Hybrid Recommended |
|
Complex multi-agent orchestration |
Strong |
Adequate |
No — LangChain native |
|
Document-heavy RAG (>1M docs) |
Adequate |
Strong |
No — LlamaIndex native |
|
Hierarchical document retrieval |
Adequate |
Strong |
No — LlamaIndex native |
|
Production workflow observability |
Strong (LangSmith) |
Adequate |
LangSmith + LlamaIndex |
|
Fine-grained retrieval control |
Adequate |
Strong |
No — LlamaIndex native |
|
Streaming + async support |
Strong |
Strong |
Either — equal capability |
|
Existing LangChain investment |
Strong |
N/A |
Stay or migrate with cause |
|
Regulated industry audit trail |
Strong (LangSmith) |
Adequate |
LangSmith layer regardless |
The Hybrid Stack Pattern
For organizations that need strong retrieval and strong workflow orchestration, the answer is not to pick one framework and compromise on the other—it's to run a hybrid stack where LlamaIndex owns the retrieval layer and LangGraph owns the workflow layer. This is architecturally clean because both frameworks expose well-defined Python interfaces. LlamaIndex's query engines can be wrapped as LangChain tools and called from LangGraph nodes.
# Hybrid stack: LlamaIndex retrieval inside LangGraph workflow
from llama_index.core import VectorStoreIndex, StorageContext
from langchain.tools import Tool
from langgraph.graph import StateGraph
# LlamaIndex handles retrieval
def llamaindex_retrieve(query: str) -> str:
engine = index.as_query_engine(similarity_top_k=5)
return str(engine.query(query))
# Wrap as LangChain tool for LangGraph
retrieval_tool = Tool(
name="document_retrieval",
func=llamaindex_retrieve,
description="Retrieve relevant documents from the enterprise corpus"
)
# LangGraph owns the agent workflow
workflow = StateGraph(AgentState)
workflow.add_node("retrieve", retrieval_node)
workflow.add_node("synthesize", synthesis_node)
workflow.add_node("validate", validation_node)
workflow.add_conditional_edges("validate", route_decision)The Observability Requirement: LangSmith
Regardless of which framework you choose for retrieval and orchestration, LangSmith belongs in your stack as the observability layer. LangSmith provides trace-level visibility into every LLM call, retrieval operation, and tool invocation. For production systems—especially in regulated industries—this trace data is what your security team needs for incident investigation and what your compliance team needs for audit evidence.
LangSmith integrates with LlamaIndex through OpenTelemetry instrumentation, so you get the same observability regardless of which retrieval framework you're running. The observability choice should be independent of the framework choice.
Migration Risk Assessment
If you are on LangChain and considering migrating to LlamaIndex for better retrieval, the migration cost scales with three factors: the number of custom chains in your codebase, the complexity of your prompt templates, and the depth of LangChain integrations you've used. Before committing to migration, run a retrieval quality comparison on your specific corpus. If LlamaIndex's retrieval advantage is less than 15% on your task, the migration cost likely exceeds the quality benefit.
Production Readiness Checklist
☑ Framework selection driven by documented retrieval and orchestration requirements
☑ LangSmith or equivalent observability deployed regardless of framework choice
☑ Retrieval quality benchmark run on production corpus before framework decision
☑ Migration cost estimate includes custom chain rewrite + integration work
☑ Hybrid stack architecture validated with integration tests across framework boundaries
☑ Framework version pinned in requirements.txt; update policy documented
☑ Breaking change monitoring configured (LangChain and LlamaIndex both move fast)
☑ Performance regression tests cover retrieval latency and accuracy after framework updates
What I Would Build Differently
The 70% quarterly rebuild rate for regulated enterprise AI stacks suggests that most teams are making framework decisions based on tutorials and GitHub stars rather than production requirements. I would invert the decision process: start with your compliance and observability requirements (which are usually fixed), then select the framework that makes those requirements easiest to satisfy, and only then optimize for feature coverage.
References
1. LangChain Blog
2. LlamaIndex Blog
3. LangSmith
4. Prem AI LangChain vs. LlamaIndex 2026
5. LangGraph Docs
Comments (0)
Join the conversation!