

I took one concrete feature — a Git-style commit message generator — and implemented it three ways: pure prompting, few-shot with retrieval, and a small fine-tune. The results changed how I think about when fine-tuning is actually worth the complexity.
The Experiment
Last month I shipped a commit message generator for our internal CLI tool. Simple feature: read the diff, produce a conventional commit message. The kind of thing that sounds trivial until you need it to work reliably across 50 different diff shapes.
I built it three ways. First, pure prompting with GPT-4o — a carefully crafted system prompt with five examples baked in, roughly 2,500 tokens per request. Second, few-shot with retrieval — I stored 200 hand-written commit messages in a vector DB and pulled the three most similar examples per request. Third, a fine-tuned GPT-4o-mini on 800 human-written examples from our actual repo history.
The goal was not to find a winner in abstract. It was to measure accuracy, drift over time, infrastructure cost, and iteration speed on a real product feature that had to ship.
What the Numbers Said
Pure prompting hit 74% format compliance on day one. Fine-tuning started at 93%. The retrieval approach landed in between at 82%. But accuracy is only part of the story.
The fine-tuned model's inference cost was dramatically lower. At our volume of roughly 10,000 requests per day, the fine-tuned model eliminated a 400-token system prompt from every request, saving approximately $0.12 per 1,000 requests. According to recent pricing data from Price Per Token, training a GPT-4o-mini fine-tune on 100K tokens costs about $0.90 — which means the training cost paid for itself in under a day at our volume.
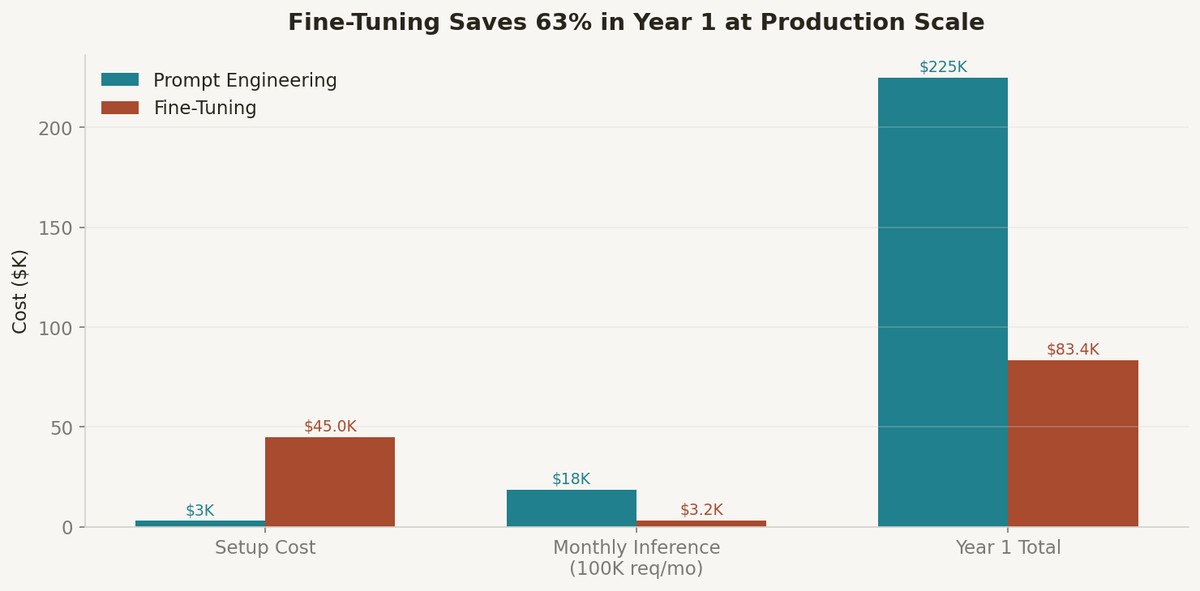
At production scale, the math is unambiguous. Stratagem Systems' analysis shows fine-tuning can deliver 50-75% reduction in inference costs versus prompt engineering, with Year 1 savings of $141K (63%) despite higher upfront costs for a 100K request-per-month workload. The break-even point occurs after just 2.9 months.
Where Fine-Tuning Actually Broke Down
Here is what the tutorials do not tell you: fine-tuning introduces a maintenance tax. Every time our codebase conventions changed — we adopted a new module naming pattern in February — the fine-tuned model kept generating the old format. Retraining took three days including data curation.
Pure prompting adapted in minutes. I changed the system prompt, pushed to production, and the new format was live. For a fast-moving startup, that iteration speed matters more than most people admit.
The retrieval approach was the surprise performer for maintenance. Adding new examples to the vector DB was trivial, and format compliance tracked within 2% of the fine-tuned model after the first month. Sebastian Raschka has written extensively about this trade-off in his Ahead of AI newsletter — the complexity ceiling of retrieval-augmented approaches is significantly lower than fine-tuning.
The Decision Framework
After this experiment, I use a simple rubric: if you are processing more than 50K requests per month on a stable, well-defined task, fine-tune. If your task definition changes more than once a quarter, use retrieval-augmented prompting. If you are prototyping or running low volume, pure prompting is the right default.
The Artificial Analysis benchmarks confirm what I found empirically — the cost-per-task gap between prompted and fine-tuned models widens non-linearly with volume. At 10K daily requests, fine-tuning saves around $15K per month. At 1K daily requests, the savings do not justify the maintenance overhead.
One thing I would do differently: start with the fine-tuning data collection pipeline on day one, even if you ship with prompting first. The 800 examples that powered my fine-tune came from logging production outputs and having engineers rate them over four weeks. That feedback loop is the real asset — the model is just a snapshot of it.
|
|
References
1. Price Per Token — Fine-Tuning Pricing 2026 — https://pricepertoken.com/fine-tuning
2. Stratagem Systems — LLM Fine-Tuning Business Guide — https://www.stratagem-systems.com/blog/llm-fine-tuning-business-guide
3. Sebastian Raschka — Ahead of AI Newsletter — https://magazine.sebastianraschka.com/
4. Artificial Analysis — Model Performance — https://artificialanalysis.ai/
5. EleutherAI Evaluation Harness — https://github.com/EleutherAI/lm-evaluation-harness
Comments (0)
Join the conversation!