

4 min read
|
A team tried to fix sparse enterprise datasets by flooding them with synthetic samples, breaking evaluation and governance in the process. This article presents decision frameworks for generating, storing, and validating synthetic data with a trade-off table for synthetic vs. real data across AI workloads. |
The Synthetic Data Trap
The team had a legitimate problem: 800 labeled examples for a document classification task that needed at least 5,000 to train a reliable model. The solution seemed obvious—generate synthetic examples using GPT-4o, scale the dataset, train the classifier. Three months later, the classifier had 94% accuracy on the evaluation set and 61% accuracy on production documents. The evaluation set was synthetic. The production documents were real.
This is the model collapse warning made concrete. When a model trained on synthetic data is evaluated against synthetic data, it can achieve arbitrarily high scores while completely failing on the real distribution. 85% of AI projects fail due to poor data quality according to Gartner, and synthetic data misuse is an increasingly significant contributor to that statistic.
The synthetic data market is growing from $0.68 billion in 2025 to $3.02 billion by 2030 at a 34.5% CAGR. That growth reflects genuine utility—synthetic data solves real problems. But it also reflects hype that's driving teams to use it in contexts where it will harm their systems.
When Synthetic Data Legitimately Helps
There are four use cases where synthetic data provides genuine, measurable value:
Privacy-preserving training. When real data contains PII, PHI, or other regulated information, synthetic data can replicate the statistical properties of the real dataset without the privacy exposure. This is the strongest use case. The synthetic data is used for training, and evaluation always uses real holdout data.
Rare event augmentation. If your production distribution includes rare but important events (fraud patterns, equipment failures, adverse drug reactions), synthetic generation of those rare events can improve recall without contaminating the majority-class distribution. Key constraint: the synthetic rare events must be generated with domain expert involvement, not pure LLM generation.
Infrastructure and load testing. Synthetic data for load testing, schema validation, and pipeline smoke tests is entirely appropriate. There is no model training involved; the data just needs to conform to the schema and volume requirements.
Instruction-tuning data generation. Generating instruction-following examples (question-answer pairs, classification labels, structured extraction targets) from real documents is effective when the source documents are real and the LLM is only generating the labels, not the documents themselves. This distinction matters enormously.
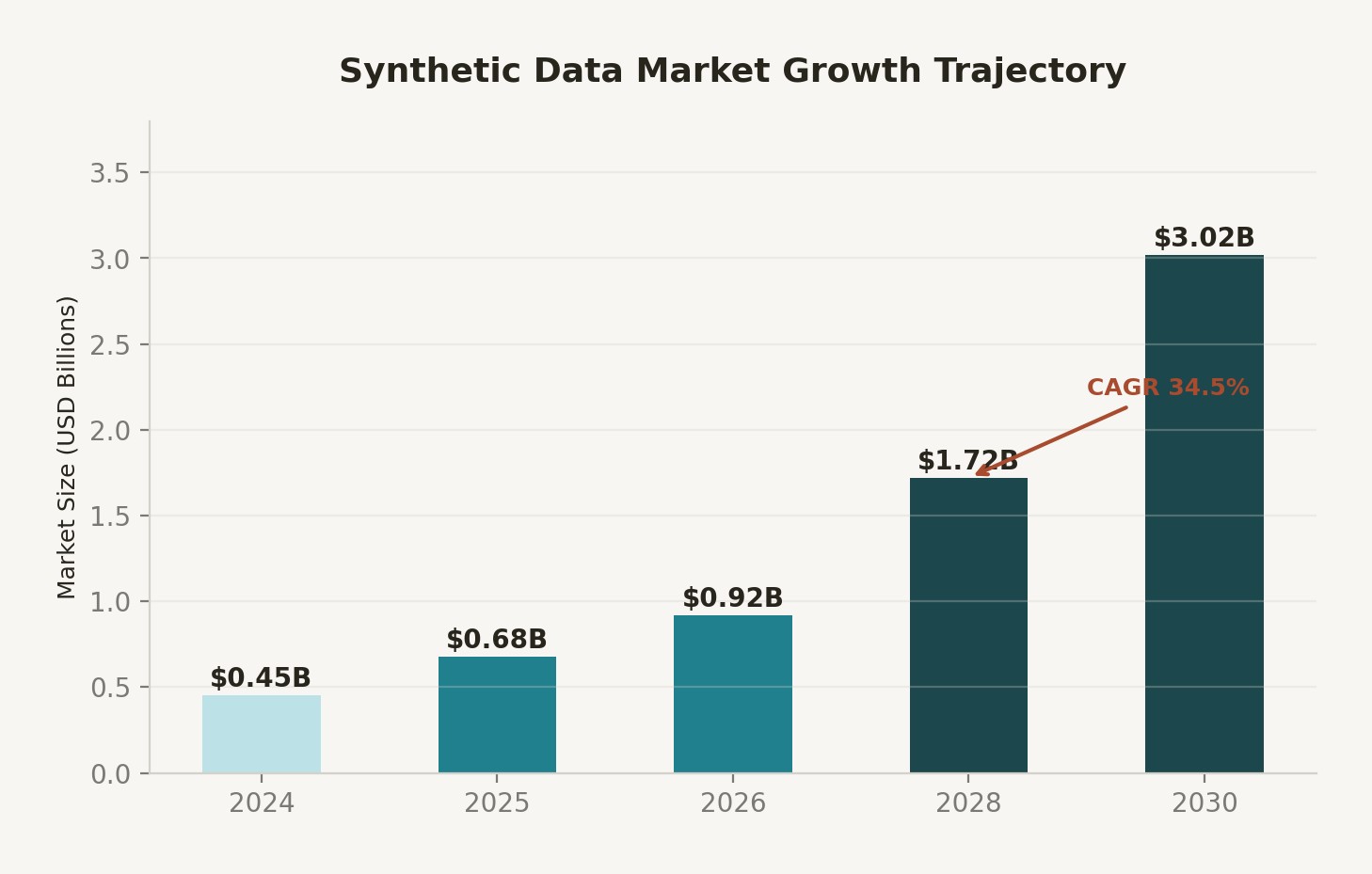
Figure 1: Synthetic data market growth trajectory 2025–2030. BFSI represents the largest vertical at 23.25% of total market share.
The Decision Framework
|
Use Case |
Synthetic Appropriate? |
Real Data Requirement |
Key Risk |
|
Model pre-training |
No |
Always required |
Model collapse via recursive training |
|
Fine-tuning (domain adapt) |
Partial — labels only |
Source docs must be real |
Distribution shift if docs synthetic |
|
Evaluation / test sets |
No — never |
Always real holdout |
Inflated metrics, production failure |
|
RAG corpus expansion |
Caution — QA pairs only |
Source docs must be real |
Hallucinated facts in retrieval |
|
Privacy-safe training |
Yes — with validation |
Held-out real data for eval |
Statistical artifact injection |
|
Rare event augmentation |
Yes — with expert review |
Real examples as seeds |
Expert bias in generation |
|
Infrastructure testing |
Yes — fully appropriate |
None required |
Schema drift if not maintained |
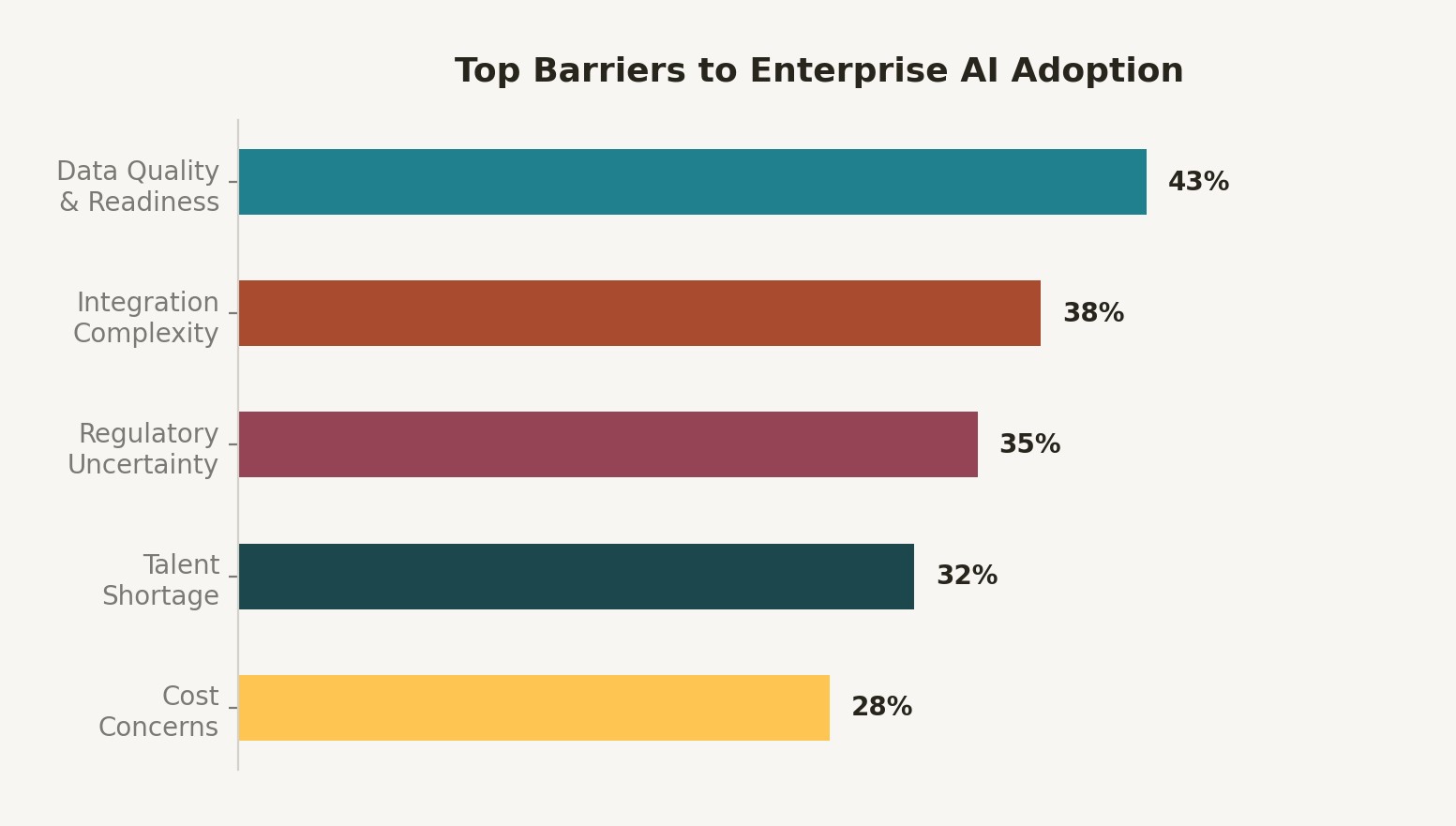
Figure 2: Primary data barriers to enterprise AI production deployment. Data quality and governance top the list for the third consecutive year.
Validation Architecture for Synthetic Data
If you are going to use synthetic data, you need a validation pipeline that would catch the failure I described at the opening. The pipeline has three required checks:
Distribution alignment test. Use statistical distance measures (Wasserstein distance, Maximum Mean Discrepancy) to verify that the synthetic dataset's feature distribution matches the real dataset. If the distance exceeds your threshold, reject the synthetic batch. Great Expectations can automate this check in your data pipeline.
Downstream task evaluation on real holdout. Before any synthetic data enters training, run a model trained exclusively on the proposed synthetic data against your real holdout set. If the synthetic-only model scores more than 5% below the real-data baseline, the synthetic data is not representative enough to be useful.
Model collapse detection. In any iterative generation pipeline—where synthetic data from generation N feeds generation N+1—measure output diversity across generations using entropy metrics. Declining diversity is the early warning signal for model collapse. Stop the pipeline before collapse, not after.
Feature Store Integration
Synthetic data should be tracked in your feature store alongside real data, with explicit metadata distinguishing synthetic origin. Hopsworks and Feast both support data origin tracking. When a model is trained on a mix of real and synthetic features, that ratio must be logged as a model artifact. This is not optional for regulated industries—auditors will ask.
43% of CDOs cite data quality as their number one obstacle to AI deployment according to the Informatica CDO Insights 2025 report. Synthetic data that isn't properly validated and tracked converts a data quality problem into a data quality crisis.
Production Readiness Checklist
☑ Evaluation and holdout sets composed entirely of real, labeled data
☑ Synthetic data used only for training, never for evaluation
☑ Distribution alignment validated against real data before training use
☑ Downstream task evaluation on real holdout required before synthetic data acceptance
☑ Model collapse detection active for any iterative generation pipeline
☑ Synthetic data origin tagged in feature store with generation metadata
☑ Real-to-synthetic ratio logged as model artifact for each trained model
☑ Domain expert review required for rare-event synthetic generation
☑ dbt lineage tracking extended to cover synthetic data transformations
What I Would Build Differently
The team that experienced the synthetic data trap could have avoided it with a single architectural rule: the evaluation set is sacred, and it is never synthetic. If you cannot afford to label a real holdout set, you cannot afford to deploy the model. This is not a resource constraint—it is a correctness constraint.
For the specific problem of sparse training data: before turning to synthetic generation, investigate active learning. Select the 100 most informative unlabeled examples for human labeling, train, repeat. Active learning often produces better models with 500 carefully selected real examples than with 5,000 synthetic examples.
References
1. Mordor Intelligence Synthetic Data Report
2. Great Expectations Docs
3. Hopsworks Feature Store
4. dbt Blog
5. Coherent Market Insights Synthetic Data
Comments (0)
Join the conversation!