

5 min read
|
Prompt tweaks in production quietly degraded a regulated workflow because there was no evaluation harness. This article reframes prompts as versioned, testable system components and shows how to wire prompt libraries into CI, regression suites, and UX telemetry. |
The Silent Degradation Problem
Six months after launch, a healthcare workflow assistant had quietly become unreliable. No incident had been filed. No alert had fired. But a clinical audit found that the system's medication reconciliation summaries had been diverging from source records at an accelerating rate since a 'minor prompt update' two months earlier. The update had never been tested. It had been deployed directly to production by an ML engineer who thought a clearer instruction would help.
This is the canonical prompt engineering failure mode in enterprise systems: prompts treated as configuration rather than code, modified without version control, deployed without evaluation, and monitored only when something visibly breaks. The HackerOne 2025 report recorded a 540% surge in prompt injection reports, but the more pervasive problem is subtler: uncontrolled prompt drift that degrades system behavior without triggering any alert.
The Correct Mental Model: Prompts Are System Components
A prompt is not a configuration value. It is a program. It has inputs (context, user query, retrieved documents), outputs (model completion), and a correctness specification (what the output should look like for a given input). That correctness specification is your evaluation suite.
Once you accept this framing, the rest follows naturally. Programs are versioned. Programs have tests. Programs go through CI before they reach production. Programs have owners. The entire software engineering discipline—built over decades—applies to prompts without modification. The failure is in not applying it.
The Prompt Report (arXiv:2406.06608) catalogues over 58 distinct prompting techniques. DSPy provides the most mature framework for programmatic prompt optimization. But the tooling is ahead of the operational practice. Most teams have the tools; they lack the process.
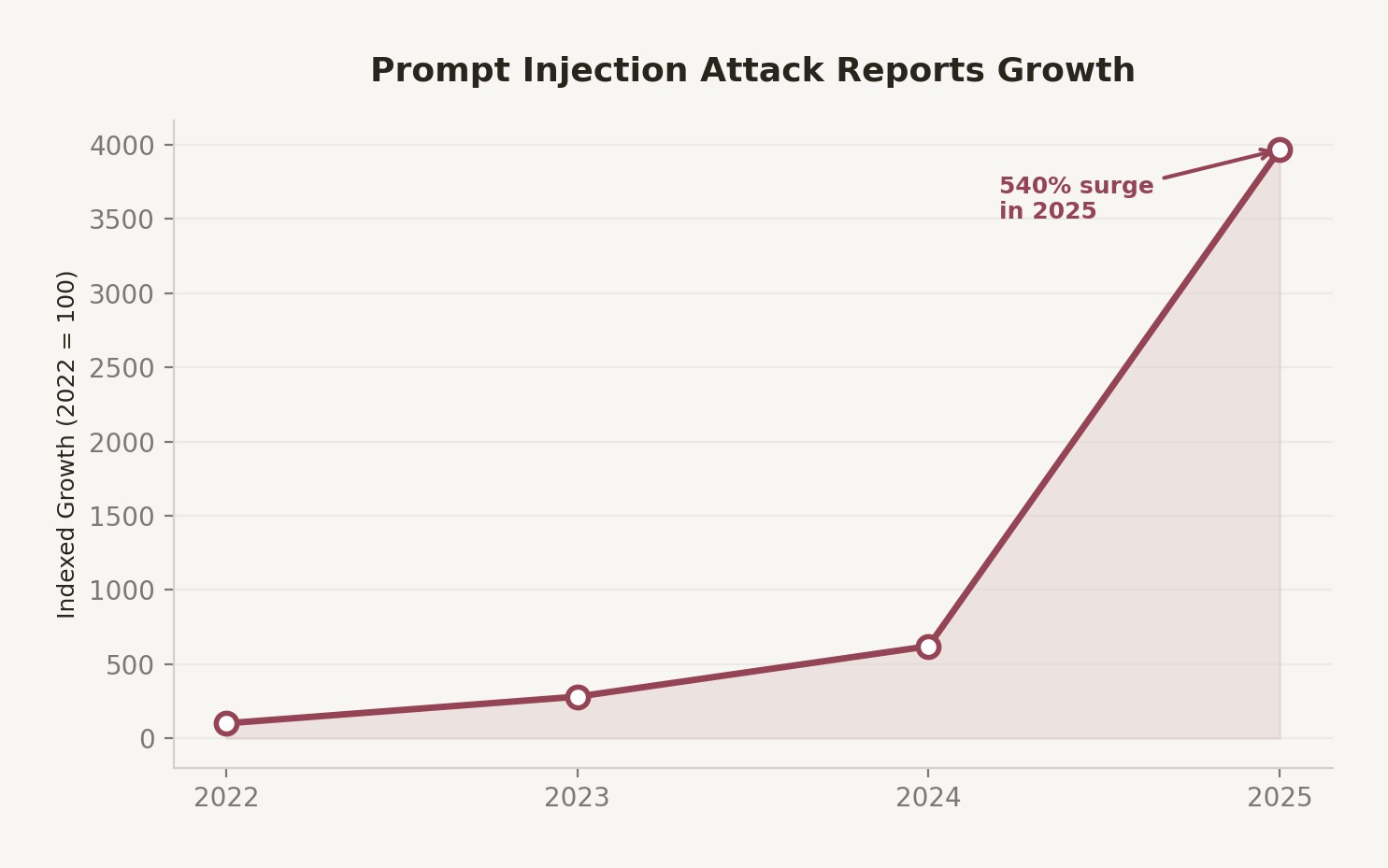
Figure 1: Prompt injection incident trends and enterprise exposure rates. 73% of production AI systems show at least one injection vulnerability vector.
Evaluation-First Prompt Architecture
The architecture has five components that must be built before any prompt goes to production:
1. Prompt Registry. A versioned store for all prompts, with schema validation. Each prompt has a name, version, input schema, output schema, and linked evaluation suite. YAML or JSON is fine; the critical property is that every change creates a new version, not an in-place mutation. Store this in your source code repository, not in a database that bypasses code review.
2. Evaluation Suite per Prompt. For each prompt, maintain a dataset of (input, expected_output) pairs. Expected outputs can be exact strings, regex patterns, JSON schema conformance, or LLM-as-judge scores—whatever is appropriate for the task. The suite should have minimum 100 examples for any production prompt, and 500+ for regulated workflows.
3. CI Integration. PROMPTFOO is the most practical open-source tool for this. Wire it into your GitHub Actions or Jenkins pipeline so that every pull request that touches a prompt file runs the full evaluation suite. A PR that degrades eval score below the threshold is blocked from merge, the same way a failing unit test blocks merge.
4. UX Telemetry Loop. Production feedback must flow back into the evaluation suite. Instrument your UX with explicit feedback (thumbs up/down) and implicit signals (correction, abandonment, regeneration). Flag low-confidence answers for human review. Use that reviewed data to expand your evaluation suite. This creates the flywheel: better evals → better prompts → better UX → more labeled data → better evals.
5. Regression Baseline. Every time you deploy a new prompt version, record the eval scores as the new baseline. Any subsequent change must beat the baseline. Never allow a prompt update that reduces eval score without explicit sign-off from the system owner.
Defense Against Prompt Injection
73% of AI systems are exposed to prompt injection vulnerabilities according to OWASP's 2025 report, and 35% of organizations have delayed AI rollouts because of it. The architectural defense is not a single control—it's a layered system:
|
Defense Layer |
Technique |
Effectiveness |
Implementation Cost |
|
Input validation |
Schema + regex guard |
Medium (bypassed by novel attacks) |
Low |
|
Instruction hierarchy |
System prompt isolation |
High (with proper separation) |
Low-Medium |
|
Output filtering |
Output schema enforcement |
High for structured outputs |
Medium |
|
Privilege minimization |
Tool call scope restriction |
Very High |
Medium-High |
|
Behavioral monitoring |
Anomaly detection on outputs |
High (catches drift) |
High |
|
Audit trail |
Immutable query + output log |
Critical for response |
Medium |
Prompt Versioning in Practice
# prompts/medication_reconciliation/v3.yaml name: medication_reconciliation version: 3.1.0 owner: clinical-ai-team eval_suite: evals/medication_reconciliation_v3.jsonl min_eval_score: 0.94 model_constraints: - provider: openai min_version: gpt-4o-2024-08-06 system_prompt: | You are a clinical pharmacist assistant. Your task is to reconcile the patient's current medication list against the discharge summary. Rules: 1. Never infer dosages not explicitly stated in the source documents. 2. Flag any discrepancy with [DISCREPANCY] marker. 3. Output must conform to the MedicationList JSON schema. 4. If source documents are ambiguous, output [UNCLEAR] not a guess. input_schema: current_meds: array[MedicationEntry] discharge_summary: string output_schema: MedicationReconciliationResult
Production Readiness Checklist
☑ All production prompts stored in versioned registry in source control
☑ Every prompt has a linked evaluation suite with minimum 100 examples
☑ CI pipeline runs eval suite on every PR touching a prompt file
☑ Eval score baseline recorded at deploy time; regression blocks future deploys
☑ UX telemetry captures explicit feedback and implicit correction signals
☑ Prompt injection defenses implemented at input, instruction, and output layers
☑ Privilege minimization applied to all tool-use prompts
☑ Behavioral monitoring deployed with alerting on output distribution drift
☑ Regulated workflow prompts have clinical/legal sign-off requirement in merge checklist
What I Would Build Differently
The healthcare team that experienced the silent degradation problem could have prevented it with two hours of setup work: a PROMPTFOO configuration file and a GitHub Actions workflow. The evaluation suite would have caught the regression within minutes of the PR being opened. The clinical audit that found the problem after two months would have been unnecessary.
For any enterprise deploying regulated AI workflows: treat the first prompt deployment as an opportunity to build the evaluation infrastructure, not as a reason to skip it because you're already behind schedule. The schedule pressure that causes you to skip eval infrastructure is the same pressure that will cause you to skip incident response when the degradation surfaces—and it will surface.
References
1. The Prompt Report (arXiv:2406.06608)
2. OpenAI Prompt Engineering Guide
3. Anthropic Prompt Engineering
4. PROMPTFOO 5. DSPy
6. SonnyLabs Prompt Injection Report
Comments (0)
Join the conversation!