

5 min read
|
A RAG system passed a demo but failed legal and audit review when pushed towards production in financial services. This blueprint defines an architecture for compliant RAG: chunking strategies, vector index sharding, retrieval-time policy filters, and data residency-aware storage. |
The Demo-to-Production Gap in RAG Systems
The demo looked perfect. The system could answer complex questions about bond covenants, pulling exact passages from a corpus of 50,000 financial documents with sub-second latency. The product manager recorded a video. Legal reviewed it and issued a stop-work order within 48 hours.
Three issues surfaced immediately. First, the vector store contained documents from multiple jurisdiction tiers—EU-regulated customer data was co-mingled with US-only research. Second, there was no retrieval-time access control: any authenticated user could retrieve any document if it was relevant to their query. Third, there was no audit trail: when an answer was produced, there was no durable record of which documents contributed to it, making retroactive compliance review impossible.
Only 31% of AI initiatives reach full production according to ISG's 2025 analysis. The RAG-specific failure rate is higher, because RAG systems have a unique compliance surface that pure inference systems don't: the retrieval layer creates new data access patterns that existing access control frameworks weren't designed to govern.
The Five Architectural Failure Modes in Production RAG
Failure Mode 1: Monolithic vector stores without access policy inheritance. Most vector databases were designed for search relevance, not access control. When you index documents into a flat vector store, you lose the ACL structure that governed access to those documents in the source system. The retrieval engine doesn't know that document X requires clearance level 3 while document Y is public.
Failure Mode 2: Chunk-level data residency violations. When a document crosses jurisdictions—a contract with EU counterparties stored in a US system—chunking it creates fragments that should be subject to different residency rules. A naive chunking strategy will embed these fragments together, creating cross-jurisdiction contamination in the vector index.
Failure Mode 3: No retrieval audit trail. RAG systems produce answers by synthesizing multiple retrieved passages. Unless you log which passages were retrieved for which query by which user, you cannot reconstruct the reasoning chain for compliance review. 73% of organizations cite security concerns as a primary barrier to RAG deployment, and audit trail absence is a leading driver.
Failure Mode 4: Embedding model versioning gaps. When you update your embedding model, the similarity space changes. Documents embedded with model v1 are not directly comparable to queries embedded with model v2. Most teams handle this by re-indexing the entire corpus—which is expensive and creates a window of inconsistency. Only 3% of organizations have full production observability for RAG pipelines.
Failure Mode 5: Missing retrieval-time reranking. Semantic similarity is necessary but not sufficient for retrieval quality. Without a reranking layer that applies freshness, authority, and domain-relevance signals, the top-k results degrade as the corpus grows.
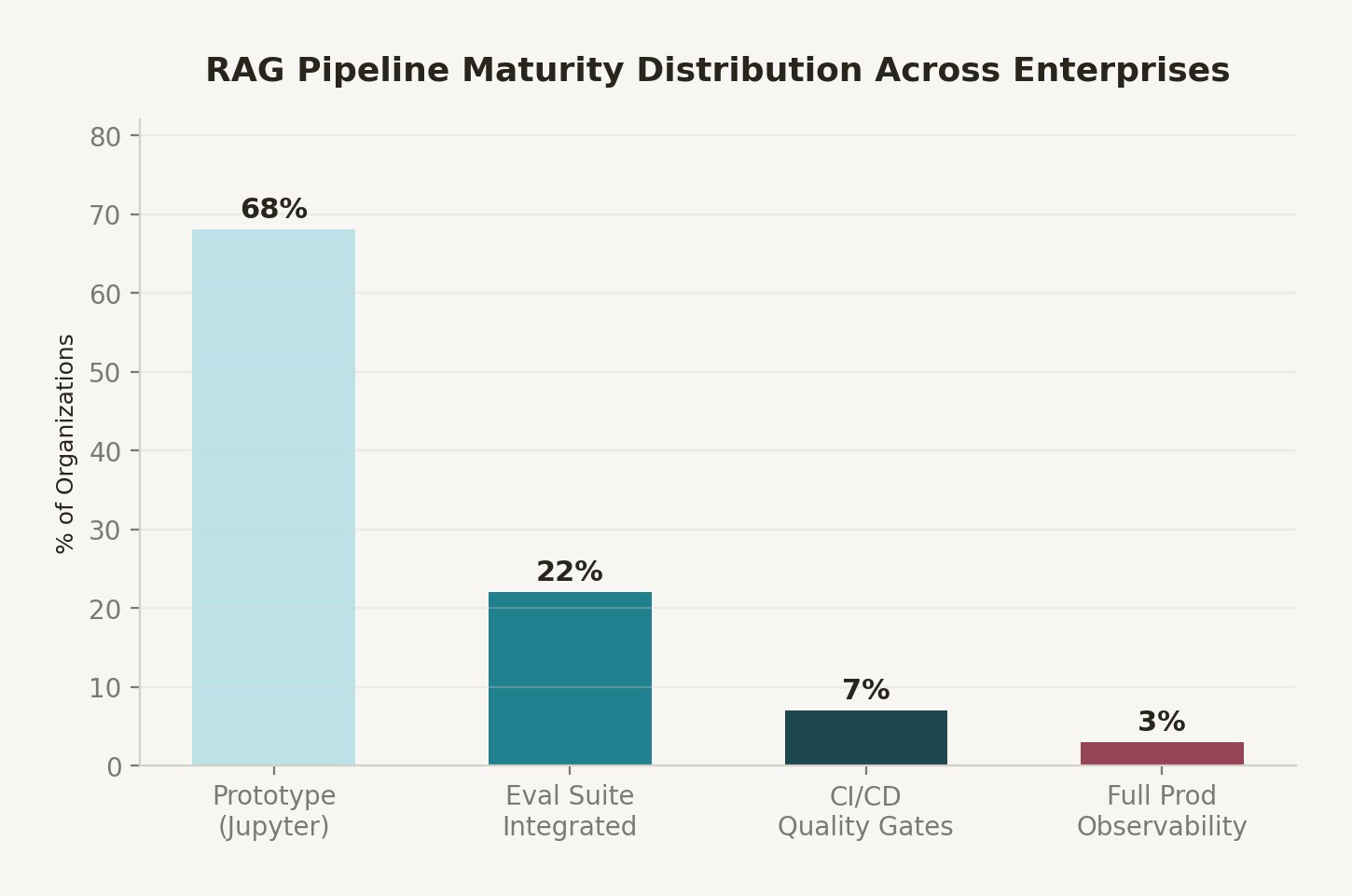
Figure 1: RAG pipeline maturity distribution across enterprise deployments. Most organizations remain at Level 1 or Level 2, lacking compliance-critical controls.
The Compliant RAG Architecture
A compliant RAG system requires six layers that most demo implementations skip entirely:
# Compliant RAG Architecture Stack Layer 1: Ingestion Pipeline Document classifier (jurisdiction, sensitivity, access tier) Metadata extraction (ACL inheritance from source) Chunking strategy (jurisdiction-aware boundary detection) Embedding with model version tracking Layer 2: Vector Store Sharding Shard per data residency region (EU, US, APAC) Shard per access tier (public, internal, restricted) Cross-shard query federation with policy enforcement Layer 3: Retrieval-Time Policy Engine User identity resolution ACL check per candidate document Jurisdiction filter (query origin vs. data residency) Reranking (freshness + authority + domain-relevance) Layer 4: Audit Trail Query log (user, timestamp, query embedding) Retrieval log (document IDs, similarity scores, ACL decisions) Generation log (retrieved passages -> final answer, model version) Layer 5: Observability Retrieval latency p50/p95/p99 (Prometheus + Grafana) Answer quality scoring (automated + human sampling) Index drift detection (embedding model version alignment Layer 6: Incident Response Per-document redaction capability (compliance-triggered) ACL retroactive update propagation Retrieval circuit breaker (kill switch per data class)
Chunking Strategies for Compliance
The chunking layer is where most compliance problems originate, and it receives the least architectural attention. There are three strategies worth knowing, each with different compliance trade-offs:
|
Strategy |
Compliance Fit |
Quality Trade-off |
Recommended For |
|
Fixed-size (512 tokens) |
Low — ignores boundaries |
High chunk fragmentation |
Internal, non-regulated corpora |
|
Sentence/paragraph |
Medium — respects structure |
Occasional semantic split |
Mixed-jurisdiction documents |
|
Semantic + jurisdiction-aware |
High — tags each chunk |
Higher compute cost |
Financial, legal, healthcare RAG |
|
Hierarchical (parent-child) |
Medium-High |
Excellent context retention |
Long-form document QA |
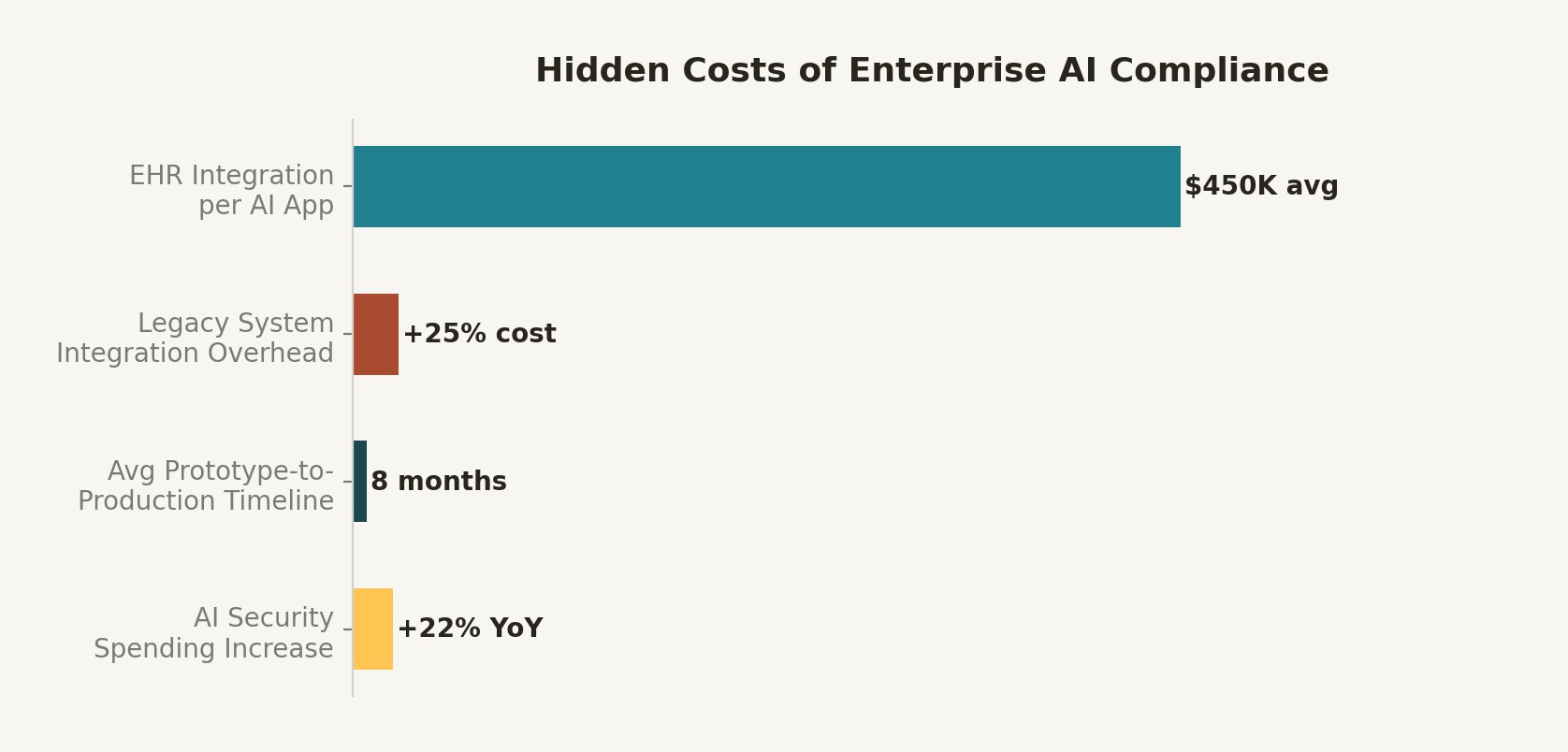
Figure 2: Compliance integration cost breakdown for enterprise RAG systems. EHR and regulated data integrations represent the largest cost category.
Vector Index Sharding Design
The sharding strategy should be driven by your data governance model, not by performance optimization. Performance can be tuned after compliance is achieved. The inverse is not true—you cannot bolt compliance onto a monolithic vector store after the fact without a full re-index.
For a typical regulated enterprise, I recommend two sharding dimensions: data residency region and access tier. This creates a matrix of shards (e.g., EU-Public, EU-Restricted, US-Public, US-Restricted) where each shard can be independently managed, audited, and—critically—deleted if a GDPR right-to-erasure request arrives. EHR integration alone costs $150K–750K per AI application; getting the shard architecture wrong multiplies that cost when remediation is required.
Retrieval-Time Policy Enforcement Pattern
# Retrieval policy enforcement (pseudocode) def retrieve_with_policy(query, user_context): # 1. Identify relevant shards for this user allowed_shards = acl_engine.get_allowed_shards( user_id=user_context.user_id, jurisdictions=user_context.allowed_jurisdictions ) # 2. Query only allowed shards candidates = vector_store.query( embedding=embed(query), shards=allowed_shards, top_k=20 ) # 3. Document-level ACL check authorized = [ doc for doc in candidates if acl_engine.check_access(user_context, doc.doc_id) ] # 4. Rerank and audit reranked = reranker.rank(query, authorized, top_k=5) audit_log.record(user_context, query, reranked) return reranked
Production Readiness Checklist
☑ Vector store sharded by data residency region and access tier
☑ Document-level ACL inherited from source system at ingestion time
☑ Chunking strategy tags each chunk with jurisdiction and sensitivity metadata
☑ Retrieval-time policy engine enforces ACL before returning candidates
☑ Full audit trail: query → retrieval decisions → generated answer, with user identity
☑ Embedding model version tracked in index metadata
☑ Re-indexing procedure documented and tested for embedding model updates
☑ Per-document redaction capability tested for compliance incident response
☑ Retrieval latency SLAs defined (p95 < 500ms recommended for interactive use)
☑ Observability dashboards deployed (Prometheus/Grafana or equivalent)
What I Would Build Differently
The system I described at the opening could have been built compliantly from the start if two decisions had been made differently. First: treat the vector store as a regulated data store from day one, with the same governance controls as the source systems. Second: build the audit trail into the retrieval API contract, not as an afterthought. When the audit trail is optional, it gets skipped under pressure. When it's part of the API signature, it gets implemented.
The AWS ML Blog and Google Cloud AI Architecture documentation both have reference implementations for compliant RAG that deserve closer study than they typically receive. Chip Huyen's blog has the best available analysis of production RAG failure modes from an engineering perspective. Read all three before writing your first index schema.
References
1. Dextra Labs Production RAG
2. Applied LLMs Guide
3. Chip Huyen Blog
4. AWS ML Blog
5. Google Cloud AI Architecture
Comments (0)
Join the conversation!