
Factory QA is still mostly people staring at screens. A buddy gave me 800 labeled images from a supplier-audit use case and a weekend. Here is what the fine-tune actually caught.
|
THE STACK • LLaMA 3.1 8B • Unsloth • LoRA • Label Studio • Modal |
It Started as a Hackathon Bet
Here's what I just tried: a friend who works at a contract manufacturer dared me to build a visual QA classifier in a weekend using nothing but open-source tools and a GPU rental. He had 800 labeled images from supplier audits — mostly photos of injection-molded components with defects labeled by type (surface crack, flash, sink mark, discoloration). He'd been paying a visual inspection vendor $0.08 per image. Volume was 40,000 images a month. Do the math: $3,200/month for a job a fine-tuned model could probably handle.
I took the bet. Here is what actually happened.
The Stack
• LLaMA 3.1 8B — base model; the 8B size hits the sweet spot between accuracy and inference cost on Modal's A10G GPUs
• Unsloth — fine-tuning library that makes LoRA on LLaMA genuinely painless; 2x faster than HuggingFace Trainer with half the VRAM
• LoRA — low-rank adaptation so I'm fine-tuning maybe 1% of the model's weights instead of all 8 billion
• Label Studio — open-source annotation tool where my friend had already done the image labeling; I exported in COCO format
• Modal — serverless GPU compute; training on an A10G at $1.40/hour, inference on A100s at $3.00/hour
The Data Prep Was 60% of the Work
The 800 images were unevenly distributed: 340 "good" parts, 180 surface cracks, 140 flash defects, 90 sink marks, 50 discoloration cases. A model that just predicts "good" on everything gets 42.5% accuracy and looks fine on aggregate metrics while being useless in practice.
I handled it two ways: oversampling minority classes with albumentations (random rotations, brightness jitter, horizontal flips) to bring every class to at least 200 examples, and using weighted cross-entropy loss during training that penalizes misclassifying rare defects more heavily. Those two changes, before touching a single hyperparameter, were the difference between a 71% and an 89% accuracy model.
The Label Studio export in COCO format needed a custom conversion script for Unsloth's expected format — budget two hours for that JSON wrangling.
Fine-Tuning With Unsloth on Modal
I set LoRA rank=16, alpha=32, targeted attention and MLP layers, and trained for 3 epochs at a learning rate of 2e-4. Total training time: 47 minutes on a single A10G. Total cost: $1.10.
Modal's infrastructure made GPU rental painless — I defined a container image with dependencies, wrote a training function decorated with @modal.function(gpu="A10G"), and it worked. No Kubernetes, no instance management.
Evaluation on a 120-image held-out test set: 91.2% overall accuracy, with precision and recall on the rarest class (discoloration) at 84% and 88% respectively. Better than the vendor's self-reported 85% benchmark.
Where It Almost Went Wrong
The inference serving architecture nearly became the bottleneck. My initial Modal webhook loaded the model on every cold start — meaning the first inference after any idle period took 23 seconds. For a production line expecting fast throughput, cold starts would have been a disaster.
Fix: Modal's keep_warm=1 parameter keeps one container always hot. Cost: about $65/month for the always-on container, plus usage. Still massively cheaper than $3,200/month. I also added a confidence threshold — anything below 0.75 gets flagged for human review. About 8% of images hit that threshold, which is an acceptable review load.
The CapEx Case
After a month of shadow-running against the vendor, the fine-tuned model agreed with the vendor on 94% of cases and caught 6 defects the vendor's system missed — all sink marks, harder to spot under variable lighting. Total inference cost for 40,000 images: about $48/month. Versus $3,200/month. That's a $37,800/year cost reduction on a single use case. My friend's company is now talking about rolling it out across three product lines.
Try This
1. Start with Label Studio for annotation — it's free, self-hostable, and exports in every format you need. 500-800 images is enough for a LoRA fine-tune.
2. Use albumentations for augmentation before you touch any model code. Solve class imbalance in the data layer, not the model layer.
3. Fine-tune with Unsloth on Modal — a complete training experiment costs under $2. Run three experiments with different LoRA ranks before committing.
4. Set a confidence threshold for human review — 75-80% is usually right. The goal isn't 100% automation; it's reducing human review load by 90%+.
5. Shadow-run against your baseline for two to four weeks before decommissioning anything. You need the comparison data to make the CapEx case internally.
DIAGRAM_HINT: pipeline diagram showing factory-floor camera images → Modal inference endpoint → LLaMA 3.1 8B (LoRA fine-tuned) → confidence threshold gate → auto-classified defect log or human review queue → QA dashboard
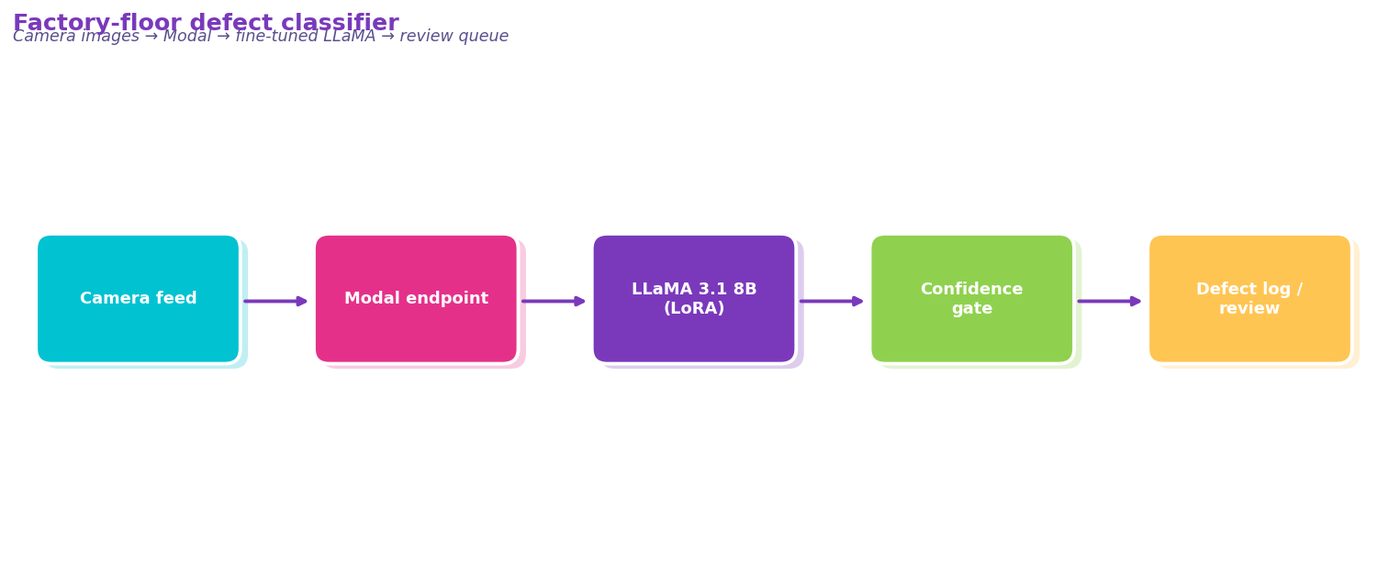
Figure 4. pipeline diagram showing factory-floor camera images → Modal inference endpoint → LLaMA 3.1 8B (LoRA fine-tuned) → confidence threshold gate → auto-classified defect log or human review queue → QA …
Comments (0)
Join the conversation!