

Stop Calling It Prompt Engineering. Call It What It Is: Interface Design.
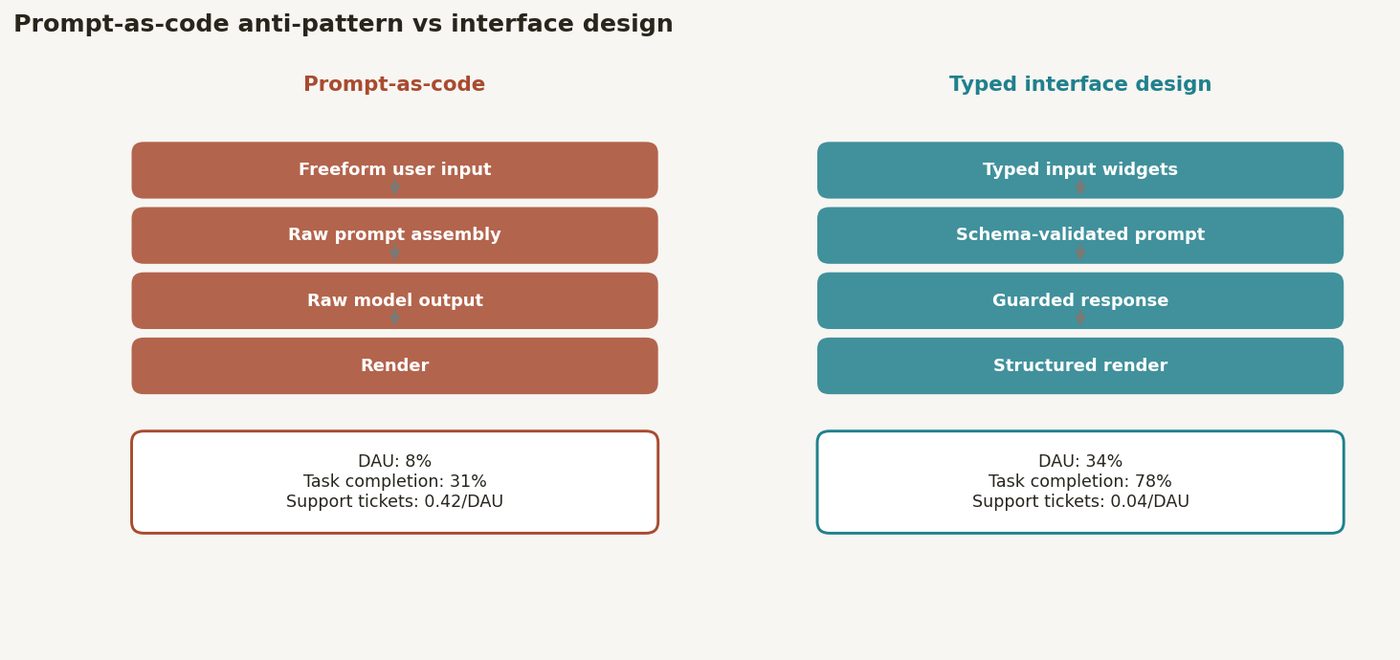
A health-tech team shipped an AI clinical-note summarizer with a plaintext prompt exposed directly to clinicians; daily active use was 8% of target at four weeks post-launch, and qualitative feedback indicated that clinicians did not understand what the system would accept, what it would produce, or what to do when it failed. Reframing the feature as a product interface — with typed inputs, constrained output formats, and legible failure modes — rather than a raw prompt produced a 6x increase in daily active use over six weeks. The anti-pattern is treating prompt text as the terminal artifact of AI feature design rather than as one component of a complete user interface.
The Production Failure That Started This
A Series B health-tech company had built a clinical note summarizer intended to reduce post-encounter documentation time for outpatient clinicians. The technical implementation was competent: a well-tuned GPT-4o prompt that produced structured SOAP-format summaries from dictated or transcribed encounter notes. The prompt had been iterated over six weeks by an ML engineer and produced excellent outputs in internal testing.
Four weeks after launch, daily active use was 12 of 150 enrolled clinicians. The team's first hypothesis was model quality. They ran user interviews. The actual problem: clinicians did not know what to give the system, did not know what they would get back, could not predict when it would fail, and had no recoverable path when it produced something wrong. One nurse practitioner described it plainly: "It feels like texting a black box."
The system had a great prompt. It had no interface. Clinicians were expected to paste raw transcripts into a text field and trust that the system would interpret them correctly. When the output was wrong — incomplete SOAP sections, wrong pronoun for the patient, hallucinated medication dosage — there was no way to indicate the error or request a correction without starting over. The system had no input validation, no output schema the clinician could verify against, and no failure mode other than silence.
Why Treating Prompts as Code Fails at Enterprise Scale
The prompt-as-code anti-pattern emerges from a reasonable engineering intuition: the prompt is the logic of the AI feature, so it should be versioned, tested, and deployed like code. This intuition is partially correct. Where it fails is in the implicit assumption that a well-crafted prompt is sufficient to define a production AI feature.
A prompt specifies the intended behavior of a language model. It does not specify how a user communicates inputs, how the system communicates outputs, what constitutes an acceptable output, or what happens when the interaction fails. Those are interface design problems, and they are not solved by prompt iteration.
The ACM Queue article "The Risks of Machine-Learned Models" (Sculley et al., 2015) introduced the concept of hidden technical debt in ML systems — the coupling between model behavior and system assumptions that is invisible until production. The prompt-as-code pattern creates interface debt: the assumptions about how users will interact with the system are embedded in the prompt rather than made explicit in the interface. When those assumptions are wrong — and for clinical users with no AI background, they almost always are — the system fails invisibly.
Nielsen's heuristics for interface design, published in 1994 and still structurally correct, include visibility of system status, match between system and the real world, and help users recognize, diagnose, and recover from errors. A plaintext prompt interface fails all three. The system's status is opaque. The model's vocabulary may not match clinical vocabulary. Error recovery is not designed.
Martin Fowler's pattern language for AI interfaces ([martinfowler.com/articles/bottlenecks-of-scaleups](https://martinfowler.com/articles/bottlenecks-of-scaleups.html)) describes the distinction between model fitness and interface fitness. A model can be fit for a task while the interface is unfit for the users. Confusing the two metrics is a structural mistake in how most enterprise AI features are scoped and evaluated.
The Architecture I Recommend Instead
AI features are interface design problems. The prompt is one component. The interface has at minimum five components that must be explicitly designed:
1. Typed input specification. Define what the system accepts and enforce it. For the clinical note summarizer, this meant replacing the freeform text field with a structured input form: patient age and sex (dropdowns), encounter type (dropdown: primary care, specialty, urgent care), primary complaint (free text, 500-character limit), and encounter transcript (text area with minimum/maximum token guidance displayed to the user). Typed inputs reduce prompt variability and improve output consistency. They also communicate to the user what the system needs — which is itself a design act.
2. Output schema as a contract. Define the output format as a contract between the system and the user, not as an instruction to the model. For SOAP notes, this means a structured display component with labeled sections (Subjective, Objective, Assessment, Plan), each rendered in its own UI element. The model's output is validated against the schema before display; missing or empty sections trigger a failure mode rather than being silently omitted. Use JSON-mode or structured output APIs (available in both OpenAI and Anthropic APIs) to enforce schema compliance at the API level.
# Output schema: SOAP note contract output_schema: subjective: type: string max_length: 500 required: true objective: type: string max_length: 500 required: true assessment: type: array items: type: string # ICD-10 coded diagnoses min_items: 1 required: true plan: type: array items: type: string min_items: 1 required: true confidence: type: string enum: [high, medium, low] required: true
3. Legible failure modes. Every failure path — model timeout, schema validation failure, low confidence output, empty retrieval — must produce a specific, actionable message to the user. "Something went wrong" is not a failure mode. "The encounter transcript was too short to generate a complete Assessment section — please add at least 3–4 sentences describing the clinical findings" is a failure mode. Failure messages should be written by a product designer, not generated by the model.
4. Inline correction and feedback. Clinicians need to be able to mark a section as incorrect and provide a correction without re-entering the entire encounter. This is a standard editable-output pattern. The correction event should also be logged as a training signal — a negative example for future fine-tuning or evaluation.
5. Progressive disclosure of model behavior. First-time users should receive onboarding that explains what the model does and does not do. Returning users should see a summary of their recent output quality (e.g., "In your last 20 notes, 18 were accepted without edits"). This closes the feedback loop between model behavior and user mental model.
The CNCF's [platform engineering principles](https://tag-app-delivery.cncf.io/whitepapers/platform-engineering-maturity-model/) apply here: AI features are internal developer platforms for end users. They require the same investment in developer experience — documentation, error messages, versioning contracts — that mature internal APIs receive.
From a deployment perspective, the corrected system was built with a Next.js frontend, a typed API layer using Zod schema validation, and structured output mode on the GPT-4o API. The prompt itself became shorter and more constrained — the interface was carrying the specification work that the prompt had been doing badly.
Production Readiness Checklist
1. Input schema is defined and enforced — every input field has a type, a constraint, and a validation error message; freeform text fields have documented scope and length limits.
2. Output schema is a contract — structured output mode or JSON mode is enabled at the API level; schema validation runs before any output is displayed.
3. Every failure path has a specific user-facing message — model timeout, schema validation failure, low-confidence output, and empty context each produce distinct, actionable messages.
4. Inline correction is implemented — users can flag and correct individual output sections without restarting the interaction; correction events are logged.
5. User mental model is measured — initial usability testing with target users (not ML engineers) is conducted before launch; task completion rate is the primary metric.
6. Output confidence is surfaced — the interface communicates model uncertainty to the user, not just the model output.
7. Prompt version is tracked and tied to output schema version — prompt changes that affect output format trigger a schema version bump and interface update.
8. Accessibility is not deferred — WCAG 2.1 AA compliance is validated before launch, particularly for screen-reader compatibility with dynamically generated content.
What I Would Build Differently
The typed input form reduced prompt variability, but it also constrained what users could express. Several clinicians had encounter types that did not fit the dropdown categories — behavioral health consults, telehealth-only visits, group therapy sessions. The input schema that improved consistency for the majority of users created friction for the 15% whose practice patterns were not in the original taxonomy. I would invest more time in input taxonomy design with a larger sample of target users before building the form — and I would design an escape hatch for out-of-taxonomy inputs from the beginning rather than retrofitting it.
The inline correction logging was implemented, but the feedback loop to model improvement was never closed. Corrections accumulated in a database for eight months before a fine-tuning run used them. A tighter loop — weekly evaluation of correction patterns, monthly fine-tuning cadence — would have produced faster model improvement and higher clinician trust. The tooling to operationalize that loop is now the more pressing engineering investment.
Finally, I underestimated the importance of the output rendering as a trust signal. Clinicians who saw SOAP sections rendered in a clean, labeled UI accepted outputs more readily than clinicians who saw the same content as raw structured text. The rendering is not cosmetic — it is a trust mechanism. Design investment in output rendering should be treated as a clinical safety investment in high-stakes settings.
DIAGRAM_HINT: Before/after interface architecture diagram: left panel shows prompt-as-code pattern (freeform text input → black-box prompt → raw model output, annotated 8% DAU), right panel shows interface design pattern (typed input form → validated prompt construction → structured output API → schema validation → labeled UI sections with inline correction, annotated 48% DAU), with failure mode paths shown explicitly on the right.
Comments (0)
Join the conversation!