
A software platform team was shipping LLM features under a test suite that asserted on exact output strings; after three post-deployment incidents within two quarters — a changed model version producing different phrasing that broke downstream parsers, a regression in a summarization feature caught only by a customer complaint, and a cost spike caused by an undetected prompt that was doubling token usage — the team rebuilt their test harness around semantic-equivalence assertions, per-test cost budgets, and adversarial evaluations. Post-deploy incidents related to LLM features fell to zero over the following two quarters. The anti-pattern is applying deterministic string-equality testing to non-deterministic LLM outputs.
The Production Failure That Started This
A B2B SaaS platform had shipped a suite of LLM-backed features over an eighteen-month period: a customer support ticket summarizer, a contract metadata extractor, and a changelog generator. Each feature had a test suite. The test suites asserted on exact output strings, generated during the initial prompt development and frozen as expected values.
Three incidents in two quarters:
Incident 1: The team updated from gpt-4-0613 to gpt-4-turbo-2024-04-09 as a cost-reduction measure. The new model produced semantically equivalent but differently phrased summaries. Downstream, a Salesforce integration was parsing those summaries with a regex that matched the old phrasing. The regex broke silently. Customer support tickets stopped syncing to Salesforce for 14 hours before a customer reported missing data. The test suite had not flagged the regression because the output was semantically correct but lexically different.
Incident 2: A prompt modification for the contract metadata extractor improved extraction accuracy on a new document type but introduced a regression on the original document type. The regression was caught by a customer three days after deployment, not by the test suite. The exact-string expected values had been generated on the original document type; the new document type was not in the test set.
Incident 3: A developer added a chain-of-thought instruction to the changelog generator prompt to improve output coherence. The instruction worked as intended on output quality. It also increased average prompt token count by 340 tokens per request. At 50,000 requests per month, this was a $2,100/month cost increase that was not detected until the month-end billing review — the test suite had no cost assertions.
All three incidents were preventable by a test harness that understood the properties of LLM outputs. None were caught by string-equality testing.
Why String-Equality Testing Fails on LLM Outputs
String-equality testing is correct for deterministic systems. An LLM output is non-deterministic by design: temperature > 0 means the same prompt produces different outputs on successive runs. Even at temperature = 0, model updates, infrastructure changes, and prompt variations produce output differences that are semantically meaningless but lexically significant. Asserting on exact strings is asserting on a property that the system does not guarantee.
The deeper problem is that exact-string tests assert on the wrong property. The property you care about for a summarizer is semantic fidelity — does the summary accurately represent the source? The property you care about for a metadata extractor is structured correctness — is the extracted JSON schema-valid and factually accurate? The property you care about for a changelog generator is format compliance and completeness. None of these properties are testable with string equality.
Chip Huyen's Designing Machine Learning Systems (O'Reilly, 2022) categorizes ML testing as covering: model tests, data tests, and system tests. System tests for LLM-backed features require assertions on semantic properties, not lexical properties. This is not a new insight — it is standard practice in information retrieval research, where metrics like ROUGE, BLEU, and BERTScore were developed precisely because lexical equality is the wrong evaluation criterion for generated text. Production test suites are ten years behind the research community on this point.
Eugene Yan's ["Testing ML Systems"](https://eugeneyan.com/writing/testing-ml/) is the most practical treatment I have read on this topic. It distinguishes between: (a) unit tests for pure functions in the ML pipeline, (b) integration tests for the pipeline as a whole, and (c) evaluation harnesses for model quality. Most teams have (a) and partial (b). Almost none have (c) running as part of CI/CD.
The Architecture I Recommend Instead
The rebuilt test harness has four components that operate at different granularities and time scales.
1. Semantic-equivalence assertions using embedding similarity. For outputs where exact phrasing is not required but meaning is — summaries, explanations, narratives — assert that the cosine similarity between the actual output embedding and the expected output embedding exceeds a threshold (typically 0.88–0.92 for text-embedding-3-small). This catches regressions where the meaning changes while allowing the phrasing to vary.
import numpy as np
from openai import OpenAI
client = OpenAI()
def embed(text: str) -> np.ndarray:
response = client.embeddings.create(input=text,
model="text-embedding-3-small")
return np.array(response.data[0].embedding)
def assert_semantic_equivalence(
actual:
str,
expected: str,
threshold: float = 0.90,
label: str = "",
) -> None:
similarity = np.dot(embed(actual), embed(expected))
assert similarity >= threshold, (
f"Semantic equivalence check failed for '{label}': "
f"similarity={similarity:.3f} < threshold={threshold}"
)
|
2. Schema-validity and constraint assertions for structured outputs. For outputs that are parsed downstream — JSON, YAML, structured data — assert on schema validity, required field presence, and value constraints. Use Pydantic models or jsonschema validation as the assertion mechanism. This is deterministic and does not depend on the LLM's phrasing.
from pydantic import BaseModel, validator
from typing import Optional
class ContractMetadata(BaseModel):
effective_date: str # ISO 8601
counterparty_name: str
contract_value_usd: Optional[float]
governing_law: str
auto_renewal: bool
@validator("effective_date")
def
validate_date_format(cls, v):
from datetime import datetime
datetime.strptime(v, "%Y-%m-%d") # raises if invalid
return v
def test_contract_extraction(pipeline,
test_document):
raw_output = pipeline.extract(test_document)
#
Will raise ValidationError if output is malformed
metadata = ContractMetadata.model_validate_json(raw_output)
assert metadata.counterparty_name
# non-empty
assert metadata.governing_law in VALID_JURISDICTIONS
|
3. Per-test cost budgets. Every test case that makes a live LLM call has an associated cost budget, expressed as a maximum token count. The test framework captures token usage from the API response and fails the test if it exceeds the budget. This is the mechanism that would have caught Incident 3: the chain-of-thought prompt change would have exceeded the per-test token budget on the first CI run.
def test_changelog_generation_cost(pipeline,
test_diff):
result
= pipeline.generate_changelog(test_diff)
assert result.usage.total_tokens <= 800, (
f"Cost budget exceeded: {result.usage.total_tokens} tokens "
f"(budget: 800). Review prompt for token efficiency."
)
|
4. Adversarial evaluation suite. A set of adversarial test cases designed to probe known failure modes: empty input, extremely long input, input containing injection attempts, input in an unexpected language, input with factual traps (content that should cause the model to abstain rather than fabricate). This suite runs weekly in CI, not on every commit, because adversarial cases are expensive and slow. The adversarial suite should be authored by someone other than the feature developer — adversarial blindspots are correlated with development blindspots.
The OWASP LLM Top 10 ([owasp.org/www-project-top-10-for-large-language-model-applications](https://owasp.org/www-project-top-10-for-large-language-model-applications/)) items LLM06 (Sensitive Information Disclosure) and LLM09 (Overreliance) define specific adversarial scenarios that should be in every enterprise LLM test suite. MITRE ATLAS AML.T0048 (Erroneous Output) should be in the test brief for high-stakes applications.
Model update protocol. When the model provider releases a new version, run the full evaluation harness — semantic equivalence tests, schema tests, cost tests, adversarial tests — against both the current and candidate model before updating. The update decision is gated on no regressions in semantic equivalence above 5% relative, no new schema validation failures, and no cost increase above 20% without explicit approval.
Production Readiness Checklist
1. No string-equality assertions exist on LLM outputs — a linting rule or code review checklist item explicitly prohibits assert output == expected_string on LLM-generated text.
2. Semantic equivalence tests cover all narrative outputs — every feature that produces free-text output has semantic equivalence tests with documented similarity thresholds.
3. Schema validation tests cover all structured outputs — every feature that produces parsed output has Pydantic or jsonschema validation tests; required fields and value constraints are asserted.
4. Per-test cost budgets are defined and enforced — every CI test that makes a live LLM call has a maximum token budget; CI fails on budget breach.
5. Adversarial test suite exists and runs weekly — adversarial cases cover at minimum: empty input, injection attempts, factual traps, and boundary-length inputs.
6. Model update evaluation protocol is documented — the process for evaluating a new model version before updating is written down and followed; the update is not a one-line version bump without evaluation.
7. Regression baseline is maintained — the evaluation harness stores results for every run; regressions are detectable by comparison to the baseline, not just to a fixed expected value.
8. Test coverage of error paths is explicit — tests exist for the behavior when the LLM API is unavailable, returns a malformed response, or exceeds the context limit.
What I Would Build Differently
The semantic-equivalence threshold of 0.90 is a judgment call that I derived empirically for this team's specific features. It is too loose for high-stakes structured decisions (a 0.90 similarity between "the contract auto-renews" and "the contract does not auto-renew" is plausibly above threshold depending on the embedding model) and too strict for stylistic narrative generation (two correct summaries of the same document should both pass). I now recommend calibrating the threshold per-feature by generating 50 pairs of correct outputs and 50 pairs of correct/incorrect outputs and finding the threshold that maximizes separation. I did not do this for the initial deployment and had to recalibrate two thresholds after false positives in CI.
The adversarial test suite is the hardest component to maintain. Adversarial cases become stale as the model and prompt evolve, and the team that builds the feature tends to build adversarial cases that probe the failure modes they anticipated, not the ones they did not. I recommend bringing in a security engineer for adversarial case authorship — someone trained in adversarial thinking rather than feature development. On two occasions, the security engineer found failure modes in the first hour that the feature team had missed in six weeks of development.
Finally, running live LLM calls in CI has a cost that compounds as the test suite grows. At 200 test cases with an average of 1,000 tokens each at GPT-4o pricing, a full CI run costs approximately $4. At five CI runs per engineer per day across a ten-engineer team, that is $200/day in CI LLM costs. I have not found a satisfying solution: mocking LLM calls removes the value of the tests; running a smaller model for most tests and the production model weekly is the best practical compromise I have implemented.
DIAGRAM_HINT: Test harness architecture diagram showing four test layers (semantic equivalence tests → schema validation tests → per-test cost budget enforcement → weekly adversarial suite) feeding into a CI/CD pipeline, with a model update evaluation gate showing before/after regression comparison, and incident timeline annotations showing the three incidents prevented by each respective test layer.
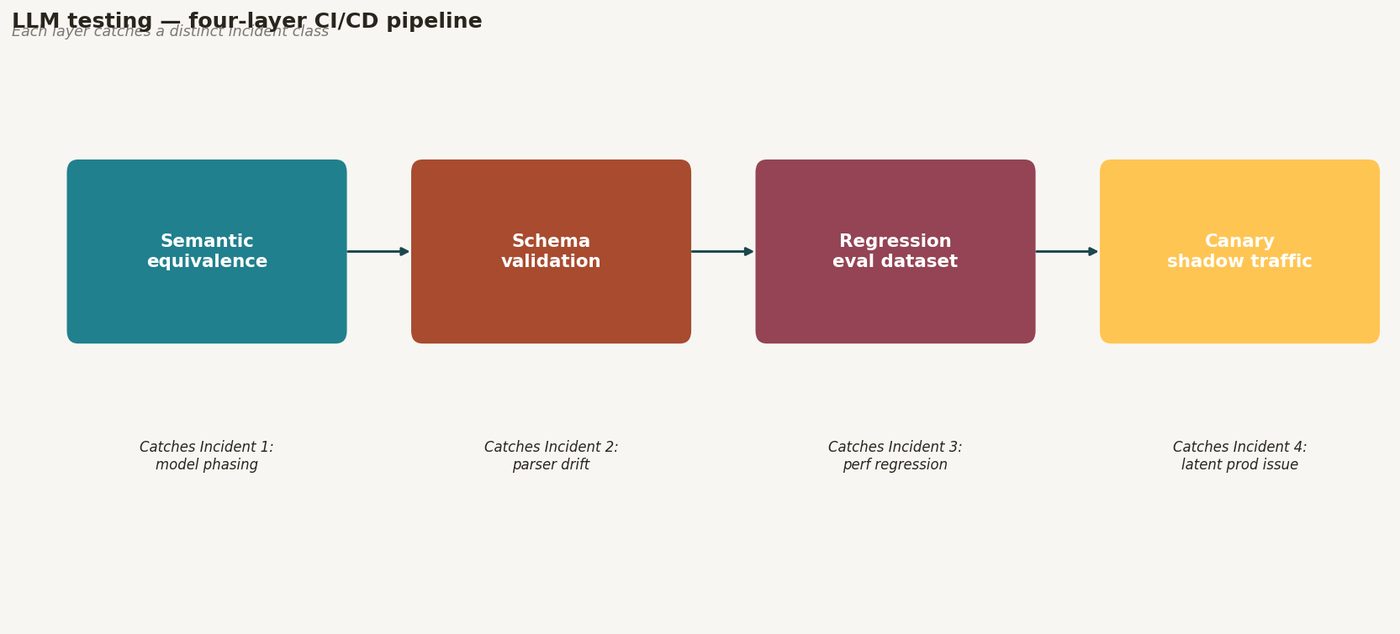
Figure 7. CI/CD pipeline diagram with four LLM test layers annotated: semantic equivalence assertions (catches Incident 1 — model version phasing change), schema validation tests (catches Incident 2 — extrac…
Comments (0)
Join the conversation!