Blueprint - Domain-Tuned RAG with Personalization and Explainability
by Admin
|
One-line summary A retrieval-augmented generation stack that grounds a foundation model in a proprietary corpus, adapts its output to a specific learner, reader, clinician, analyst or citizen, and exposes a plain-language audit trail of which sources were used and why. |
Reference architecture
|
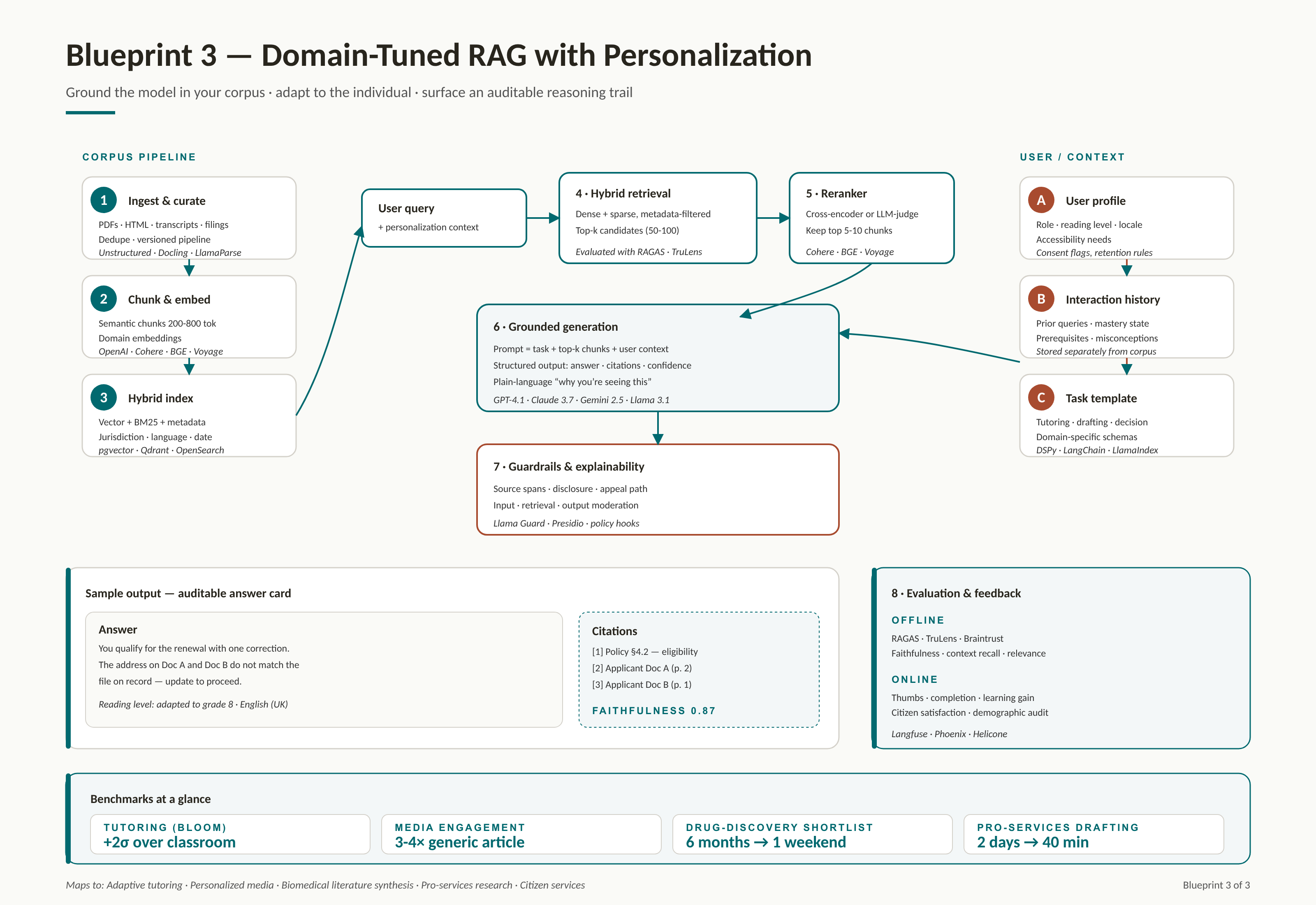
Domain-Tuned RAG with Personalization and Explainability |
|
1. Corpus ingestion and curation Versioned pipeline: load PDFs, HTML, transcripts, PubChem / PubMed, filings, learner history; de-duplicate; segment by semantic boundary; store raw + cleaned + chunked copies. |
|
▼ |
|
2. Chunking and embedding Semantic chunking (200-800 tokens, heading-aware). Embed with a domain-appropriate model - biomedical for life sciences, code for engineering, general for mixed corpora. |
|
▼ |
|
3. Hybrid retrieval Dense (vector) + sparse (BM25) + metadata filters (jurisdiction, language, reading level, publication date). Reranker (cross-encoder or LLM-as-judge) keeps the top 5-10. |
|
▼ |
|
4. User / context model Per-user state: prior interactions, prerequisite mastery, reading level, role, jurisdiction, accessibility needs. Stored separately from raw user data with clear retention rules. |
|
▼ |
|
5. Generation with grounding LLM prompt composes retrieved chunks + user context + task template. Structured output: answer, citations, confidence, and plain-language "why this is being shown to you". |
|
▼ |
|
6. Explainability and guardrails Every output ships with: sources and quoted spans, a personalization disclosure, and a recourse path (appeal, ask a human, request the un-personalized version). |
|
▼ |
|
7. Evaluation and feedback Offline - RAGAS / TruLens metrics (faithfulness, answer relevance, context recall). Online - thumbs, completion, learning gain, citizen satisfaction, demographic bias audits. |
Technology behind
|
Layer |
Recommended technology |
Notes |
|
Ingestion |
Unstructured.io, Docling, LlamaParse |
Layout-aware parsing matters for scientific PDFs and filings. |
|
Embeddings |
OpenAI text-embedding-3, Cohere Embed v3, Voyage, BGE / E5 (open) |
Pick by domain; run a retrieval eval before locking in. |
|
Vector store |
pgvector, Qdrant, Weaviate, or Pinecone |
pgvector is enough for most POCs; migrate when scale demands. |
|
Hybrid search |
OpenSearch / Elasticsearch for BM25 + vector plugin |
Keep lexical signal - identifiers, codes, names. |
|
Reranker |
Cohere Rerank, Voyage Rerank, BGE-reranker, or LLM-as-judge |
Adds 5-15 points to retrieval precision at modest latency cost. |
|
Generation |
GPT-4.1, Claude 3.7 Sonnet, Gemini 2.5, Llama 3.1 70B |
Use a smaller model for drafts, a larger one for final pass. |
|
Orchestration |
LangChain, LlamaIndex, Haystack, or DSPy for prompt optimization |
DSPy shines when you want systematic prompt search. |
|
Personalization store |
Feature store or dedicated service with explicit consent flags |
Keep user state separate from corpus; GDPR / COPPA implications. |
|
Evaluation |
RAGAS, TruLens, Arize, Braintrust, Promptfoo |
Ground truth sets per vertical; re-run on every prompt change. |
|
Safety and policy |
Llama Guard, OpenAI moderation, Presidio for PII |
Layered - input, retrieval, output. |
|
Observability |
Langfuse, Phoenix, Helicone, OpenTelemetry |
Log query, retrieved IDs, prompt, response, feedback. |
Architectural pros and cons
|
Architectural Pros |
Architectural Cons |
|
• Grounds generation in fresh, proprietary content - no retraining needed to reflect new documents. • Explainability is native: every claim can point to a source span, which is exactly what regulated and public-sector contexts require. • Personalization layer is decoupled from the corpus, so privacy controls, retention, and deletion are cleanly enforceable. • Hybrid retrieval (vector + BM25 + metadata) out-performs pure vector on identifier-heavy corpora (tickers, drug names, case numbers). • Same architecture powers tutoring, personalized media, research synthesis, drug-discovery literature review and citizen services. |
• Retrieval quality is the ceiling - if the right chunks are not returned, the LLM cannot recover by reasoning alone. • Chunking strategy is deceptively important; too small and you lose context, too large and you bury signal. • Personalization can drift toward "easier and more validating" content (education article), producing short-term metric gains without real learning. • Authenticity risk in media: AI that mimics a columnist's voice undermines the relationship even when technically correct. • Equity of access - the strongest outcomes require reliable connectivity, capable devices, and metacognitive skill; deployment can widen gaps. |
Use cases
• Adaptive tutoring: Learner model tracks mastery and misconceptions; retrieval pulls the right worked example at the right difficulty; spaced-repetition scheduling per-student; expert instructors handle motivation and high-stakes feedback.
• Personalized news / newsletter: Same underlying article rewritten for a 28-year-old early-career reader vs a 55-year-old pre-retiree; explicit disclosure that the piece was tailored; a non-personalized version always accessible.
• Biomedical literature synthesis: Foundation model fine-tuned or prompted over PubMed / PubChem generates ranked hypotheses on binding mechanisms; candidate shortlists with ADMET predictions delivered in days instead of months.
• Consulting / legal research synthesis: Hundreds of filings, memos, and precedent documents condensed into a first-draft deliverable that passes partner review with minor edits.
• Citizen-facing government service: Benefits or permit decision delivered with a plain-language explanation ("flagged because the address on two supporting documents does not match the one on file"), with an accessible human-review pathway.
• Personalized ad creative: Strategy layer (human judgment) + RAG over brand assets generates thousands of campaign variants for fast testing while preserving brand voice.
Benchmarks
|
Use case |
Baseline |
This blueprint |
Source |
|
Tutored vs classroom learning (Bloom) |
Classroom |
+2 standard deviations (tutoring) |
2-sigma problem (Bloom, 1984) |
|
AI-adaptive retention uplift |
Static curriculum |
+25-40% |
Duolingo / Khan Academy / Coursera |
|
Corporate time-to-competency |
Traditional L&D |
-30-45% |
Education article |
|
Reader-level personalized engagement |
Generic article |
3-4x engagement |
Media article |
|
Biomedical candidate shortlist time |
~6 months (team of 6) |
~1 weekend (team of 2) |
Healthcare article |
|
Professional-services drafting time |
2 days |
40 minutes |
Professional services article |
|
Research synthesis compression |
100% baseline |
50-75% reduction |
Professional services article |
|
Retrieval faithfulness (RAGAS) |
Non-grounded LLM |
0.75-0.90 on well-curated corpora |
RAGAS benchmarks |
Failure modes to plan for
• Hallucinated citations: enforce "if no chunk supports the claim, refuse"; never allow the model to invent a source.
• Stale or contaminated corpora: version the corpus, re-embed on changes, and log retrieval IDs with every response.
• Engagement-optimized learning: do not let completion rate be the only north star; measure transfer, not just satisfaction.
• Voice impersonation: distinguish AI-assisted from AI-authored content, with explicit disclosure in user-facing outputs.
• Equity gaps: plan offline modes, low-bandwidth paths, and human support so deployment narrows rather than widens access gaps.
References
Key references supporting this blueprint: [1] [2] [3] [4] [5] [6] [7] [8].
[1]Rock Health, "2024 Year-End Digital Health Funding Report," https://rockhealth.com/insights/2024-year-end-digital-health-funding-report/
[2]Jumper, J. et al., "Highly accurate protein structure prediction with AlphaFold," Nature 596, 583-589 (2021), https://www.nature.com/articles/s41586-021-03819-2
[3]Lewis, P. et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS 2020, https://arxiv.org/abs/2005.11401
[4]Bloom, B. S., "The 2 Sigma Problem," Educational Researcher, 1984, https://web.mit.edu/5.95/readings/bloom-two-sigma.pdf
[5]Khan Academy, "Khanmigo impact research," https://blog.khanacademy.org/khanmigo/
[6]Duolingo, "How Duolingo uses AI to create lessons faster," https://blog.duolingo.com/large-language-model-duolingo-lessons/
[7]Gao, Y. et al., "Retrieval-Augmented Generation for Large Language Models: A Survey," 2024, https://arxiv.org/abs/2312.10997
[8]Snowflake + LangChain benchmark on RAG latency and accuracy, https://www.snowflake.com/blog/retrieval-augmented-generation-benchmarks/