Blueprint - Agentic Document Processing and Triage
by Admin
|
One-line summary A multi-step agent that ingests a document or ticket, extracts structured fields, cross-references authoritative data, drafts a resolution, and routes only the genuinely ambiguous cases (typically 8-20%) to a human reviewer with a full context package. |
Source articles this blueprint maps to
• Financial Services - "From 30-Day Onboarding to 3 Days" (KYC, sanctions screening, compliance triage)
• Technology and Telecom - "I Pointed an AI Agent at a Telco's Trouble Tickets" (NOC Tier-1 triage)
• Real Estate - "The Appraiser in the Algorithm" (commercial due-diligence document review)
• Government - "The Last Mile of Government AI" (benefits eligibility, permits, fraud detection)
• Professional Services - "The Billing Model Is Broken" (research synthesis, first-draft generation)
Reference architecture
|
Agentic Document Processing and Triage |
|
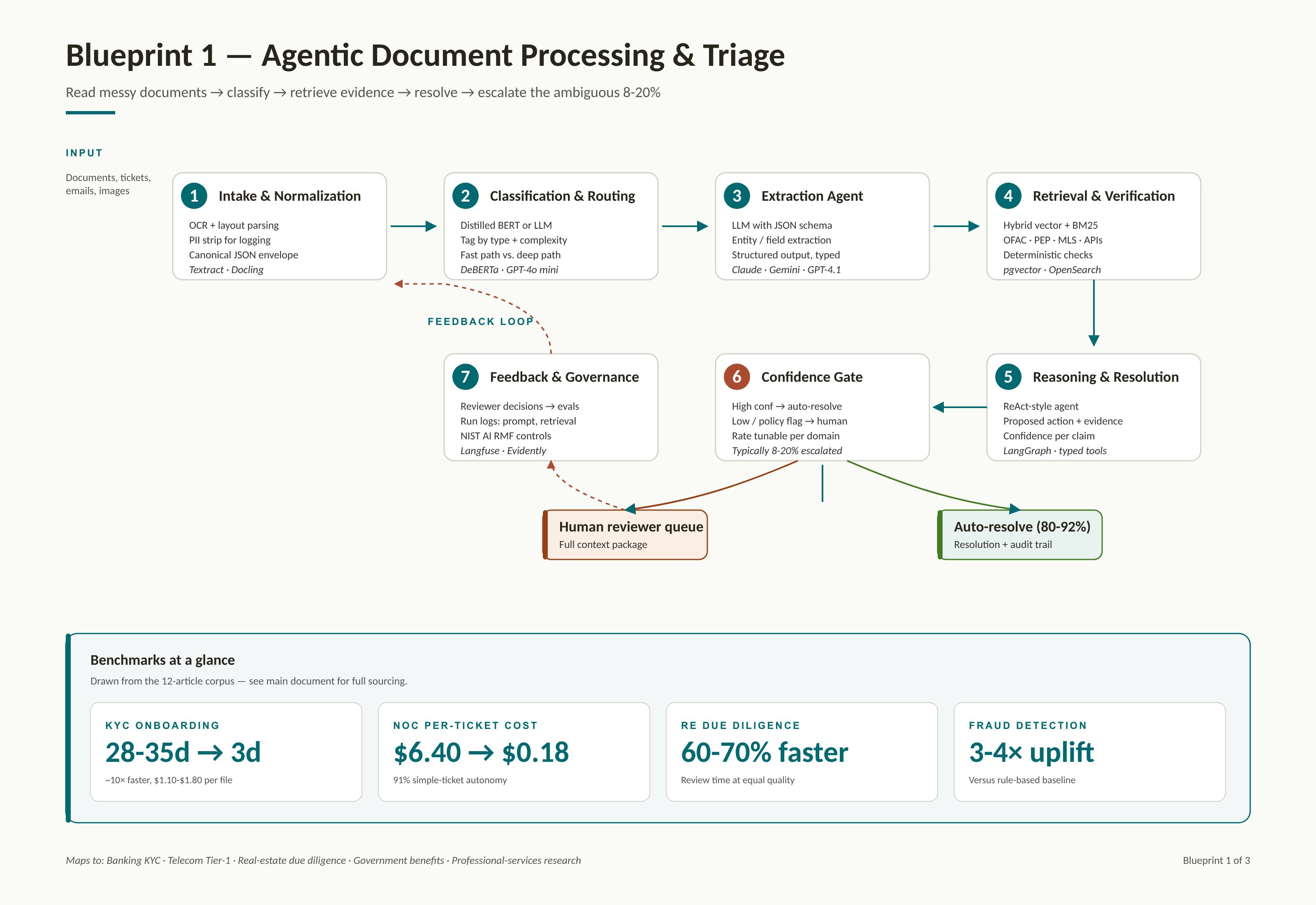
1. Intake and normalization Accept documents (PDF, image, email, ticket), run OCR / layout parsing, strip PII for logging, and emit a canonical JSON envelope with raw_text, metadata, provenance. |
|
▼ |
|
2. Classification and routing Lightweight classifier (fine-tuned BERT or LLM with function calling) tags the item by type and complexity. Simple cases go to fast path, complex cases to deep path. |
|
▼ |
|
3. Extraction agent LLM with structured output (JSON schema) extracts entities - for KYC: passport fields, beneficial owners; for tickets: device ID, symptom, region; for real estate: parties, clauses, obligations. |
|
▼ |
|
4. Retrieval and verification Vector + keyword hybrid search over runbooks, past cases, sanctions lists, regulatory text. Deterministic API calls (OFAC, PEP, MLS, permit DB) cross-reference extracted entities. |
|
▼ |
|
5. Reasoning and resolution ReAct-style agent drafts a proposed action, a confidence score per claim, and an audit trail of retrieved evidence. Enforces a JSON decision schema per use case. |
|
▼ |
|
6. Human-in-the-loop escalation Cases below confidence threshold or flagged by policy go to a reviewer queue with full context: original doc, extracted fields, evidence, proposed action, and why it was escalated. |
|
▼ |
|
7. Feedback and governance Reviewer decisions feed back into evaluation sets; every run is logged with model version, prompt hash, retrieval IDs, and outcome for audit under NIST AI RMF / regulator review. |
Technology behind
|
Layer |
Recommended technology |
Notes |
|
OCR and layout |
Amazon Textract, Azure Document Intelligence, or open-source Docling + Tesseract |
Layout-aware extraction beats raw OCR for forms and IDs. |
|
Classification |
Distilled BERT / DeBERTa or LLM function calling (GPT-4o mini, Claude Haiku, Llama 3.1 8B) |
Small models are enough for the top 10-20 categories. |
|
Extraction |
Frontier LLM with JSON schema / tool use (GPT-4.1, Claude 3.7 Sonnet, Gemini 2.5) |
Structured outputs eliminate brittle regex parsing. |
|
Retrieval |
Hybrid search: pgvector or OpenSearch + BM25; LlamaIndex or LangChain for orchestration |
Dense-only retrieval under-recalls exact identifiers. |
|
External APIs |
OFAC/PEP feeds, Companies House, DMV, MLS, Snowflake internal data |
Deterministic checks remain deterministic - do not delegate them to the LLM. |
|
Agent framework |
LangGraph, CrewAI, or a plain state machine with typed tools |
Prefer explicit state machines over open-ended autonomy in regulated contexts. |
|
Human-in-the-loop |
Label Studio, Argilla, or a custom Streamlit / Retool queue |
Reviewer UX is where most teams lose velocity - invest here. |
|
Observability |
Langfuse, Arize Phoenix, or OpenTelemetry + custom spans |
Log prompt, retrieved chunks, tool calls, final output per run. |
|
Governance |
Evidently, Giskard, Fiddler; NIST AI RMF controls |
Bias, drift, and adversarial robustness monitoring. |
Architectural pros and cons
|
Architectural Pros |
Architectural Cons |
|
• Modular - each stage (OCR, classify, extract, retrieve, decide) can be swapped without rewriting the pipeline. • Deterministic checks stay deterministic (sanctions, fraud rules), which preserves regulatory defensibility. • Confidence-driven escalation produces a clean economic story: humans only see the 8-20% that matter. • Audit trail is a first-class artifact, so it works in regulated verticals (banking, healthcare, public sector). • Feedback loop turns every reviewer decision into training / evaluation data at near-zero marginal cost. |
• Latency accumulates - 5-7 LLM calls per item can push p95 past 10 seconds without careful batching. • Cost grows linearly with volume; no free lunch at million-item scale without distillation. • Hard to debug when an agent "confidently produces a resolution that was correct for the category it had inferred, but wrong because the category inference was wrong" (telco article). • Context-starvation failures dominate - upstream intake quality matters more than model choice. • Regulatory posture varies by jurisdiction; the same agent may need different guardrails per region. |
Use cases
• KYC and onboarding: Passport, utility bill, incorporation certificate ingestion; PEP / OFAC cross-check; compliance summary drafted, ~8% routed to a human reviewer; end-to-end under 60 seconds per file.
• NOC Tier-1 ticket triage: Classify trouble ticket, pull top-3 relevant historical incidents plus runbook section, propose a resolution with a confidence score, escalate with a structured briefing when confidence is low.
• Commercial real-estate due diligence: Lease, title, zoning and environmental document review; flag non-standard clauses; 60-70% reduction in review time at consistent quality.
• Government benefits and permits: Eligibility checks, permit renewal processing; plain-language decision explanations; transparent appeal path; public bias monitoring reports.
• Professional-services research synthesis: Read hundreds of filings / reports, extract the points that matter, generate a first-draft deliverable that passes partner review with minor edits.
• Fraud detection (public sector and finance): Anomaly flags on claims, procurement, tax filings; reported 3-4x detection rate versus rule-based systems with fewer false positives.
Benchmarks
Published figures from the source articles and reference deployments:
|
Use case |
Baseline (human) |
This blueprint |
Source |
|
KYC onboarding time |
28-35 days |
3 days |
Banking article |
|
KYC unit cost |
$10-$14 per file |
$1.10-$1.80 per file |
Banking article |
|
Telecom Tier-1 simple ticket resolution |
~90% (human first-pass) |
91% agent-autonomous |
Telecom article |
|
Telecom Tier-1 complex ticket resolution |
~63% (human first-pass) |
63% agent-autonomous |
Telecom article |
|
NOC per-ticket cost |
$6.40 |
$0.18 |
Telecom article / Gartner AIOps |
|
NOC staffing reduction |
0% (baseline) |
30-40% within 24 months |
Gartner AIOps |
|
Real-estate DD review time |
100% (baseline) |
30-40% (60-70% faster) |
Real-estate article |
|
Fraud detection rate |
1x (rules-based) |
3-4x with fewer false positives |
HMRC / government article |
Failure modes to plan for
• Document quality: low-resolution, angled photos of IDs remain the dominant extraction-error driver.
• Adversarial inputs: AI-generated identity documents are already in the wild; the detection arms race is real.
• Context starvation: structured intake forms and telemetry enrichment at ticket creation were worth more than model upgrades in the telco experiment.
• Over-automation in citizen contexts: even correct decisions fail publicly when a person cannot understand or appeal them.
References
Primary sources and further reading supporting this blueprint are attached as footnotes in-line: [1] [2] [3] [4] [5] [6] [7].
[1]McKinsey & Company, "The state of AI in 2024 and a half decade in review," https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
[2]Financial Action Task Force, "Opportunities and Challenges of New Technologies for AML/CFT," https://www.fatf-gafi.org/en/publications/Digitaltransformation/Opportunities-challenges-new-technologies-for-aml-cft.html
[3]Gartner, "Market Guide for AIOps Platforms," https://www.gartner.com/en/documents/4022225
[4]Yao, S. et al., "ReAct: Synergizing Reasoning and Acting in Language Models," ICLR 2023, https://arxiv.org/abs/2210.03629
[5]NIST AI Risk Management Framework 1.0, https://www.nist.gov/itl/ai-risk-management-framework
[6]OpenTelemetry, observability standard, https://opentelemetry.io/
[7]HMRC, "Annual Report and Accounts 2023-24," https://www.gov.uk/government/publications/hmrc-annual-report-and-accounts-2023-to-2024
Comments (0)
Join the conversation!